Hoy en día, es impensable para cualquier empresa que servicios como el correo electrónico o el análisis de datos en tiempo real (BIG DATA), no estén disponibles de manera permanente.
‘Aquí y ahora’ es la filosofía del XXI. No tenemos tiempo para intentarlo más tarde y no hay una segunda oportunidad.
En este contexto, disponer de los servicios de manera permanente, lo que a nivel técnico se conoce como alta disponibilidad, o HA, por sus siglas en inglés, es clave.
El usuario final quiere que siempre se atiendan sus peticiones en el momento que se realizan, y es poco transigente al fallo. No podemos decepcionarlo.
El desafío se encuentra en que los errores, desafortunadamente, existen. Por robusto que sea el sistema, una máquina podría dejar de funcionar o el servicio no responder, con lo que dejaríamos de atender peticiones.
Incluso si todo va bien, siempre que necesitemos actualizar los sistemas para introducir mejoras, nuevas funcionalidades, o simplemente corregir bugs, la disponibilidad del sistema se verá comprometida.
Por ello, disponer de un sistema en alta disponibilidad, que tiene que funcionar y además estar disponible 24x7, es hoy en día una condición prácticamente indispensable.
Pero ¿de qué estamos hablando exactamente?
La Alta Disponibilidad de un sistema está basada en 3 conceptos fundamentales: Redundancia, Detección y Capacidad de recuperación.
Alcanzar un sistema en alta disponibilidad está intrínsicamente relacionado con la Redundancia, de tal forma que si una máquina deja de funcionar se pueda disponer de otra que realice el trabajo en su lugar.

Si disponemos de un clúster donde los servicios de los distintos nodos trabajan de manera coordinada, si uno de los nodos falla, los demás salen al rescate y se encargan de realizar el trabajo requerido. Para garantizar alta disponibilidad en el clúster se redunda el software y se debería redundar también el hardware.
Tan importante como la redundancia es la capacidad de detección del fallo, es decir, saber cuándo un servicio no funciona correctamente para balancear su trabajo a otros servicios disponibles.
Finalmente es importante la capacidad de recuperación del servicio, que permite volver a restaurar el estado de alta disponibilidad anterior al fallo.
La no disponibilidad del sistema puede implicar perdida de información que dependiendo de la función del servicio podría ser vital para las operaciones de la empresa. Por ello, hoy en día, se hace prácticamente imprescindible blindar los servicios críticos a través de alguna solución de persistencia de la información.
Nuestra solución
Como expertos en MuleSoft y de Apache Ignite, nos propusimos fusionar lo mejor de ambas tecnologías para alcanzar un sistema de alta disponibilidad basado en Mule, enriquecido con funcionalidades de Apache Ignite.
El reto: dotar a la versión comunidad de Mule de alta disponibilidad, con escalabilidad horizontal, procesamiento distribuido, tolerancia a fallos y persistencia.
Para ello desarrollamos una extensión del core de Mule que funciona de forma totalmente transparente - es decir, una vez instalado y configurado podrás seguir trabajando con normalidad - pero disfrutando de la clusterización como una herramienta más.
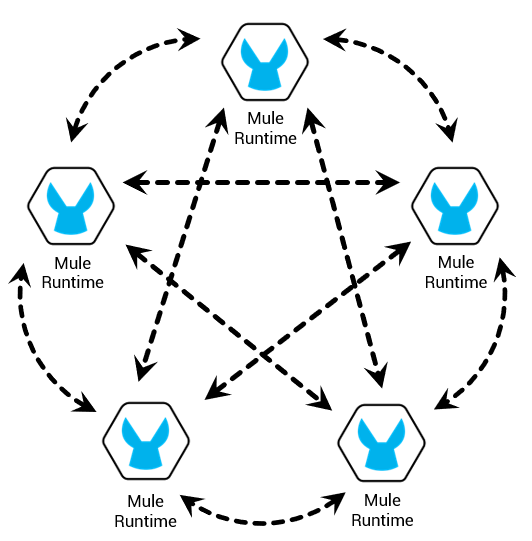
Dicha Extensión del Core de Mule está formada por una serie de Factorías alternativas a las que proporciona Mule por defecto, para gestionar sus colas VM, Store y Cerrojos (Locks).
Básicamente, la funcionalidad de esta extensión de core es convertir las Colas VM, los Store y los Cerrojos (Locks) en estructuras distribuidas en clúster para repartir cargas de trabajo, almacenar datos y coordinar procesos.
Con esto conseguimos que tanto los desarrollos existentes como los nuevos funcionen en clúster de forma transparente.
Además, al no afectar al desarrollo de tus proyectos, tienes la capacidad de migrarlos a la versión Enterprise sin perder un ápice de tu trabajo.
Ahora podrás dotar a tu versión de Mule de:
- Alta Disponibilidad sin limitación en el número de instancias de Mule
- Escalabilidad horizontal
- Persistencia distribuida de la información
- Tolerancia a fallos
La extensión del core de Mule, aunque potente, está limitada al API del core de Mule. Para superar sus limitaciones hemos desarrollado unos conectores para Apache Ignite y GridGain que enriquecen sustancialmente las capacidades de procesamiento distribuido de la información dentro de tus aplicaciones de Mule. Profundizaremos en sus beneficios en una próxima entrada del blog.