¿Has oído hablar de GridGain o Apache Ignite? ¿Te gustaría conocer sus principales características? Entonces sigue leyendo mientras te presentamos esta plataforma.
¿Qué es Apache Ignite?
Apache Ignite® es una plataforma de almacenamiento y procesamiento de datos en memoria, que puedes usar como base datos distribuida, sistema de mensajería, streaming y un largo etcétera, para crear aplicaciones escalables con alta tolerancia a fallos.
Apache Ignite fue liberado como código abierto a finales del 2014 por GridGain Systems bajo licencia Apache 2.0.
¿Qué es GridGain?
La plataforma de computación en memoria GridGain® está construida sobre las características principales de Apache Ignite®. GridGain, que sigue el modelo de código abierto, agrega capacidades muy valiosas a Ignite en las ediciones GridGain Enterprise y Ultimate para mejorar la administración, la monitorización y la seguridad en entornos de producción de misión crítica.
Mira la comparativa entre GridGain y Apache Ignite para más información.
Arquitectura
Apache Ignite is a memory-centric distributed database, caching, and processing platform for transactional, analytical, and streaming workloads delivering in-memory speeds at petabyte scale.
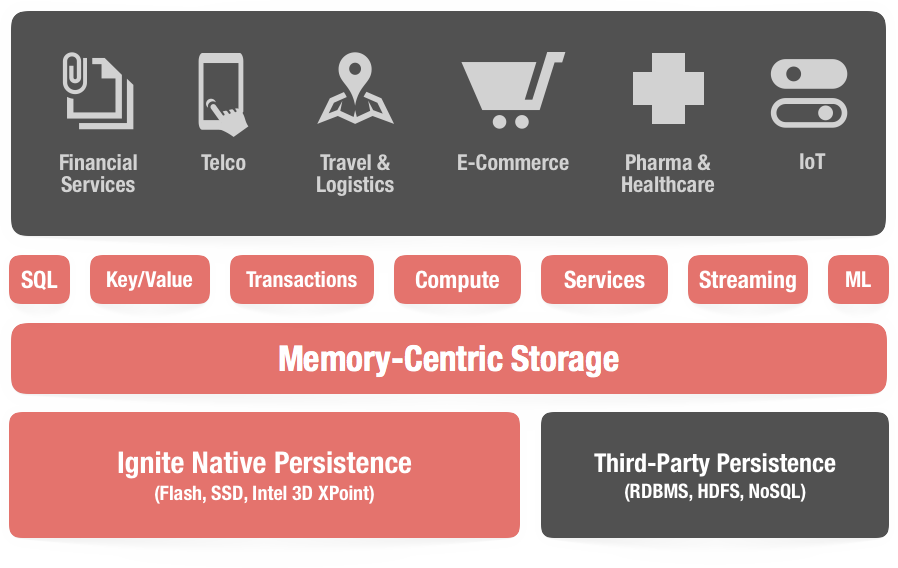
La pieza clave de Ignite es el almacén clave-valor distribuido en memoria, a partir del cual se han creado otras estructuras y servicios que son los que conforman la plataforma de Apache Ignite.
Apache Ignite data grid is an in-memory distributed key-value store that can be viewed as a distributed partitioned hash map with every cluster node owning a portion of the overall data. This way the more cluster (server) nodes we add, the more data we can cache.
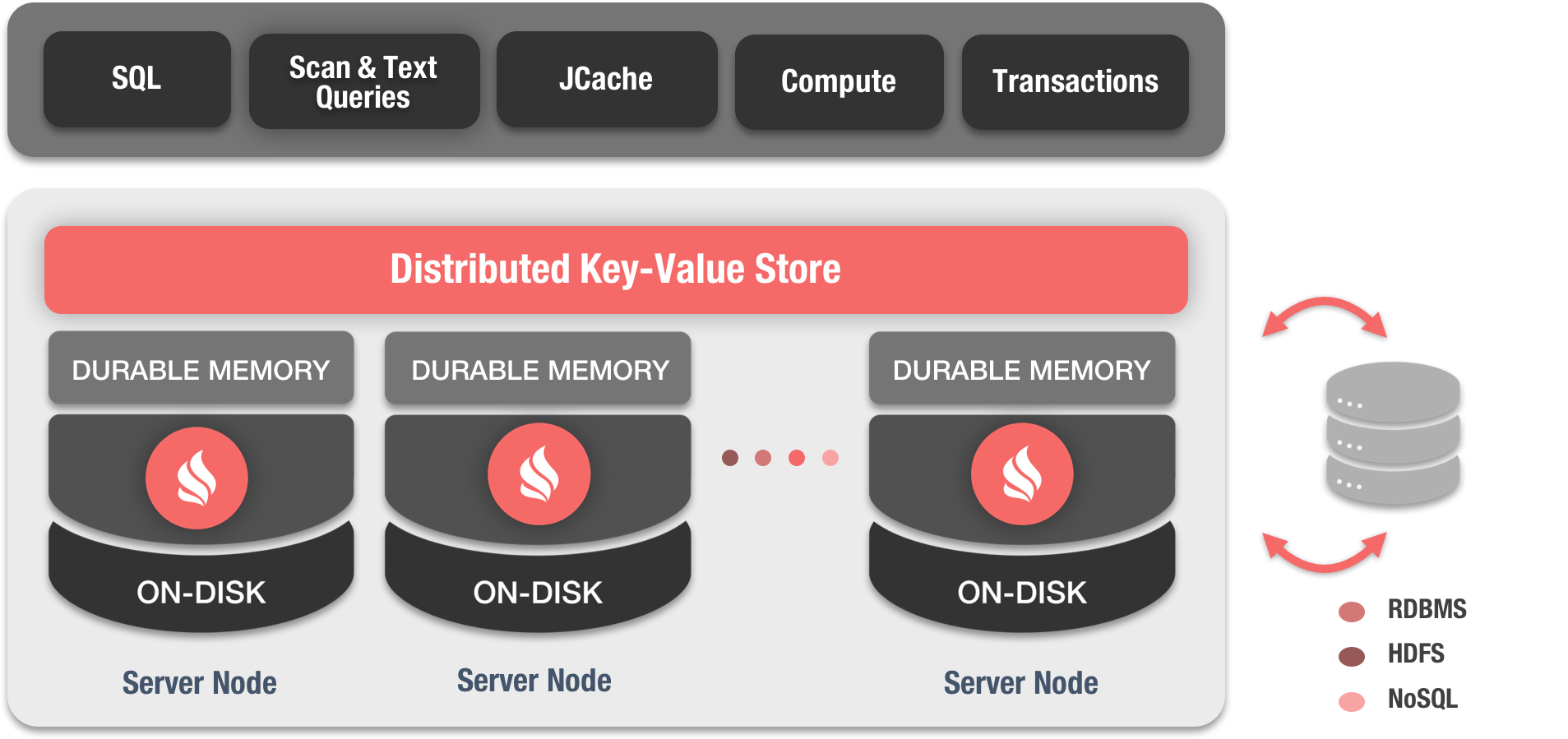
Características
Estas son algunas de sus características más relevantes:
- Código abierto, implementaciones en diferentes lenguajes.
- Tecnología madura y en constante evolución.
- Amplia comunidad de usuarios.
- Mucha y muy buena documentación con ejemplos prácticos.
- Completamente modular y desacoplado.
- Ofrece una amplia gama de servicios.
- Almacenamiento en memoria (Durable Memory).
- Computación colocada.
- Integridad ACID.
- Administración, monitorización y seguridad mejoradas para entornos de producción de misión crítica con GridGain®.
Modular y desacoplado
Ignite está diseñado de forma completamente modular y desacoplada, lo que permite cargar los módulos que necesites a la carta, y optimizar los recursos necesarios para correr tus aplicaciones.
Amplia gama de servicios
Ofrece una amplia variedad de servicios, entre los que destacan:
- Almacenamiento distribuido de datos
- Clave/Valor (Cache)
- Base de datos (SQL/Lucene[1])
- Sistema de ficheros en memoria (IGFS)
- Estructuras de datos distribuidas
- Colas (Queue)
- Conjuntos (Set)
- Atómicos (Atomic types)
- Semáforos (Semaphore)
- Cuenta atrás (CountDownLatch)
- Cerrojos (Lock)
- Secuencias (ID Generator)
- Transacciones distribuidas
- Transacciones ACID en clúster que garantizan la consistencia
- Mensajería
- Queue
- Topic
- Eventos
- Ingesta de datos y streaming
- Carga de datos y streaming que permite ingestar grandes volúmenes de datos.
- Servicios distribuidos
- Despliegue de servicios definidos por el usuario en clúster.
- Aprendizaje automático (Machine Learning)
- Pre-procesamiento (extracción y normalización)
- Algoritmos de clasificación
- Algoritmos de regresión
- Algoritmos de recomendación
- Algoritmos de clustering
- Integración con otras tecnologías
- Spring data
- TensorFlow
- Spark
- Kafka
- Camel
- JMS
- MQTT
- Storm
- Flink
- Flume Sink
- ZeroMQ
- RocketMQ
- …
Almacenamiento en memoria
La principal ventaja de Ignite respecto de otras soluciones es que usa directamente la RAM del sistema para almacenar y procesar los datos, lo que la convierte en una de las plataformas más eficientes en la actualidad.
Algunos datos sobre RAM y discos SSD/NVMe:
- La tasa típica de transferencia de RAM esta comprendida entre 2GB/s-25GB/s, mientras que discos SSDs/NVMe están entre 200MB/s-4GB/s para lecturas/escrituras secuenciales.
- Las latencias de lecturas/escrituras aleatorias en RAM son del orden de nanosegundos, mientras que en discos SSD/NVMe son del orden de microsegundos.
Teniendo en cuenta estos datos, nos podemos hacer una idea del increíble rendimiento que se obtiene al usar directamente la RAM para almacenar y procesar datos.
Otra ventaja de usar directamente la RAM del sistema es que no se ve afectada por las pausas del GC (recolector de basura) de la JVM.
Pero, si almacenamos los datos en la RAM, ¿qué ocurre si el sistema se cae?
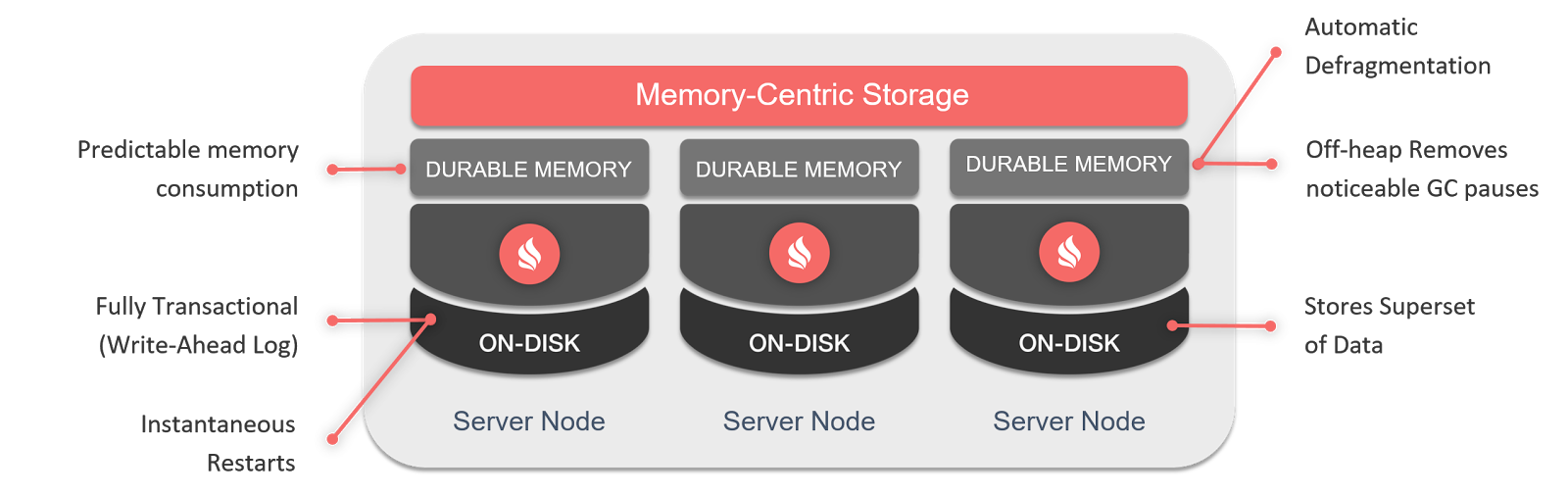
Ignite implementa Durable Memory que garantiza completamente la consistencia y la persistencia de los datos ante un eventual fallo parcial/completo del clúster y, por supuesto, que el clúster esté completamente operativo, sin necesidad de precarga de datos, tras un reinicio.
The Apache Ignite memory-centric platform is based on a durable memory architecture that allows storing and processing data and indexes both in memory and on disk when the Ignite Native Persistence feature is enabled. The durable memory architecture helps achieve in-memory performance with the durability of disk using all the available resources of the cluster.
Computación colocada
Ignite, permite enviar cálculos ligeros únicamente a los nodos que contienen los datos, es decir, colocar cálculos con datos. Como resultado, Ignite escala mejor y minimiza el movimiento de datos, a diferencia de la mayoría de las bases de datos tradicionales, que funcionan de manera cliente-servidor, lo que significa que los datos deben llevarse al lado del cliente para su procesamiento, requiere un gran movimiento de datos de los servidores a los clientes y generalmente no se escala.
Echa un vistazo al artículo sobre los beneficios de la computación colocada.
Integridad ACID
Los datos almacenados en Ignite cumplen con ACID (Atomicity, Consistency, Isolation and Durability) tanto en memoria como en disco, por lo que Ignite es un sistema muy consistente.
Las transacciones de Ignite funcionan a través de la red y se pueden distribuir entre múltiples servidores.
¿Cómo empiezo a trabajar con Apache Ignite o GridGain?
Incorporar Apache Ignite o GridGain en una aplicación Java con maven es muy simple. Puedes encontrar más ejemplos en Apache Ignite examples.
Otros lenguajes
Ignite proporciona implementaciones para diferentes lenguajes de programación como java, C++, C#, Python, node.js, por lo que integrarlo en tus aplicaciones no será costoso.
Arquitecturas híbridas
Permite que aplicaciones diseñadas en los diferentes lenguajes soportados puedan comunicarse entre sí usando la misma tecnología: Ignite.
La configuración es bastante sencilla. Necesitarás:
Añadir la dependencia
ignite-core- obligatorio - eignite-spring- puesto que vamos a usar una configuración a través de spring - en el pom.xml de tu aplicación. Puedes usar la dependencias de Apache Ignite o de GridGain.Dependencias de Apache Ignite:
<dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-core</artifactId> <version>${ignite.version}</version> </dependency> <!-- optional, spring configuration --> <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-spring</artifactId> <version>${ignite.version}</version> </dependency>Dependencias de GridGain:
<dependency> <groupId>org.gridgain</groupId> <artifactId>ignite-core</artifactId> <version>${gridgain.version}</version> </dependency> <!-- optional, spring configuration --> <dependency> <groupId>org.gridgain</groupId> <artifactId>ignite-spring</artifactId> <version>${gridgain.version}</version> </dependency>
Crear un fichero spring con la configuración para Ignite, al que llamaremos, por ejemplo
ignite-config.xml.Configuración mínima de un nodo de Ignite:
- Nombre de la instancia (
gridName)[2] - Tipo de nodo (
clientMode)[3] - Directorio de trabajo (
workDirectory)[4] - Mecanismo de descubrimiento (
discoverySpi)[5]
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="a-ignite-config" class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="gridName" value="an-ignite-grid" /> <property name="clientMode" value="false" /> <property name="workDirectory" value="/opt/ignite/work" /> <property name="discoverySpi"> <bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"> <property name="localPort" value="45500" /> <property name="localPortRange" value="10" /> <property name="ipFinder"> <bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder"> <property name="shared" value="true"/> </bean> </property> </bean> </property> </bean> </beans>- Nombre de la instancia (
Configuración
Ten en cuenta que esta es una configuración mínima con descubrimiento local a través de TCP.
Echa un vistazo a la documentación oficial para explorar todas las opciones disponibles (otros mecanismos de descubrimiento, persistencia, hilos, logger, etc).
La configuración también se puede crear programáticamente, aunque personalmente recomiendo el uso del fichero spring ya que nos permitirá usar distintas configuraciones en función del entorno de ejecución, por ejemplo, para cambiar el mecanismo de descubrimiento (discoverySpi), sin tener que modificar los binarios de nuestra aplicación.
- Crear una instancia de Ignite para acceder a su API.
Ignite ignite = Ignition.start("ignite-config.xml"); [...] // gets or creates a cache with default configuration IgniteCache cache = ignite.getOrCreateCache("my-cache"); cache.put(theKey, theValue);
Conclusiones
Ignite es una potente herramienta, indispensable si necesitas crear aplicaciones escalables con alta tolerancia a fallos.
Ofrece una amplia gama de servicios, que te permitirán, entre otras cosas:
- Almacenar datos en modo clave-valor hasta explotarlos y analizarlos usando SQL/Lucene y/o ML.
- Crear accesos exclusivos a recursos (Locks, Semaphores) en clúster.
- Ingestar datos de forma eficiente aprovechando las implementaciones que proporciona de fábrica o creando las tuyas.
- Usar colas y topics para establecer comunicaciones y/o distribuir la carga computacional de forma eficiente entre servicios y aplicaciones.
- Administración, monitorización y seguridad mejoradas para entornos de producción de misión crítica con GridGain®.
Sin duda, Ignite puede ser considerado como el “todo en uno” de la computación distribuida.
Preguntas frecuentes
¿Puedo tener diferentes instancias de Ignite corriendo en la misma JVM?
Sí. De hecho, esta característica es muy interesante si decidimos implementar una arquitectura formada por diferentes clústers de Ignite para separar cargas de trabajo, junto con aplicaciones/servicios que necesitan acceder a varios clústeres a la vez.
- Arquitectura con un único clúster de Ignite:
- Arquitectura con varios clústers de Ignite para evitar un posible impacto negativo en el rendimiento, por ejemplo, para que la base de datos no se vea afectada por procesos analíticos que normalmente tienen un consumo de CPU alto:
En este sentido, Ignite no impone ninguna restricción, incluso puedes tener múltiples instancias en modo servidor agrupadas en diferentes clústeres corriendo en la misma JVM (Java Virtual Machine).
Otras preguntas frecuentes respondidas por el equipo de Apache Ignite.
- 1.El motor de búsqueda Lucene que proporciona Apache Ignite de fábrica soporta búsquedas textuales. ↩
- 2.Nombre con el que se registrará la instancia de Ignite en la JVM local. ↩
- 3.Modo en el que se arranca la instancia de Ignite (cliente, servidor). ↩
- 4.Directorio en el Ignite guardará los artefactos que necesite. Debe ser único por instancia. ↩
- 5.Mecanismo que se utilizará para registrar/agrupar/descubrir nodos que formarán parte del mismo clúster (TCP, UDP, kubernetes, Amazon S3...). ↩