Have you ever heard of GridGain or Apache Ignite? Would you like to know its main features? Then come with us as we introduce you to this platform.
¿What is Apache Ignite?
Apache Ignite® is a in-memory data storage and processing platform, which you can use as a distributed database, messaging system, streaming and a long etcetera, to create scalable applications with high fault tolerance.
Apache Ignite was open-sourced by GridGain Systems in late 2014 under Apache License 2.0.
¿What is GridGain?
The GridGain® in-memory computing platform is built on top of the core features of Apache Ignite®. GridGain, which follows the open core model, adds highly valuable capabilities to Ignite in the GridGain Enterprise and Ultimate Editions for enhanced management, monitoring and security in mission-critical production environments.
See GridGain vs Apache Ignite comparison for more info.
Architecture
Apache Ignite is a memory-centric distributed database, caching, and processing platform for transactional, analytical, and streaming workloads delivering in-memory speeds at petabyte scale.
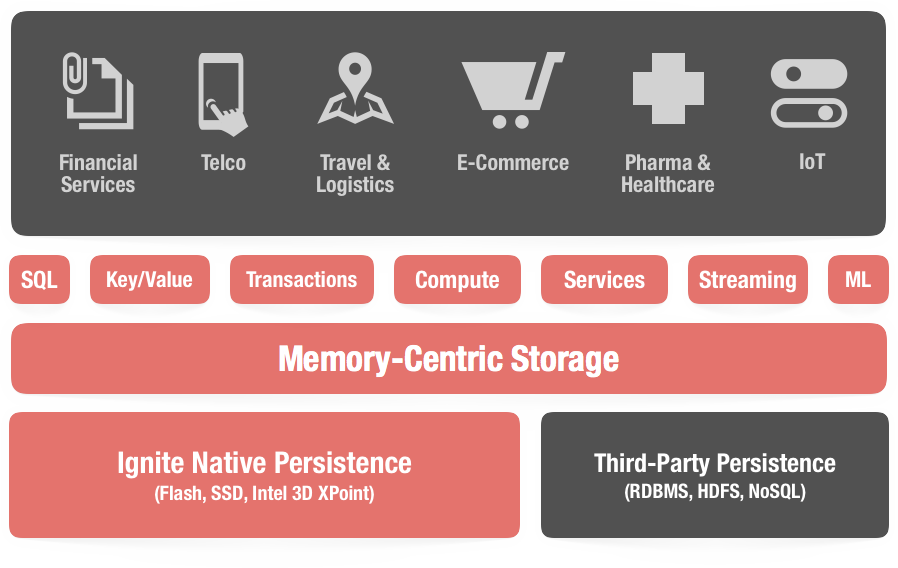
Ignite’s cornerstone is the in-memory distributed key-value store, from which other structures and services have been created that make up the Apache Ignite platform.
Ignite data grid is an in-memory distributed key-value store that can be viewed as a distributed partitioned hash map with every cluster node owning a portion of the overall data. This way the more cluster (server) nodes we add, the more data we can cache.
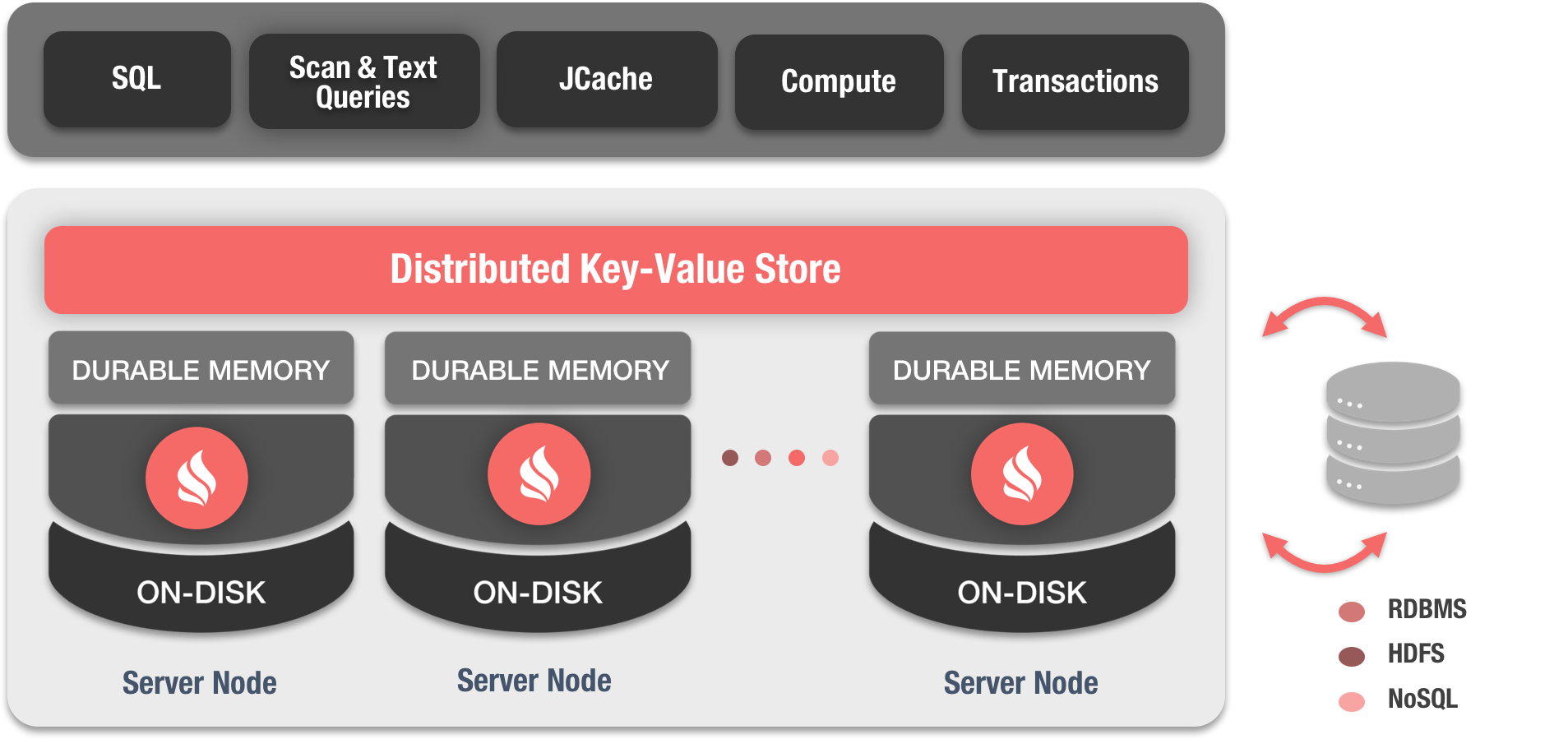
Features
These are some of its most relevant features:
- Open source, implementations in different languages.
- Mature and constantly evolving technology.
- A large community of users.
- Extensive and very good documentation with practical examples.
- Completely modular and decoupled.
- It offers a wide range of services.
- Memory storage (Durable Memory).
- Collocated computation.
- ACID database integrity.
- Enhanced management, monitoring and security for mission-critical production environments with GridGain®.
Modular and decoupled
Ignite is designed to be completely modular and decoupled, allowing you to load the modules you need à la carte, thus optimizing the resources needed to run your applications.
Wide range of services
It offers a wide range of services, including:
- Distributed data storage
- Key/Value (Cache)
- Data base (SQL/Lucene[1])
- In-Memory File System (IGFS)
- Distributed data structures
- Queus
- Set
- Atomic types
- Semaphore
- CountDownLatch
- Lock
- ID Generator
- Distributed transactions
- Clustered ACID transactions that ensure consistency
- Messaging
- Queue
- Topic
- Event
- Data ingestion and streaming
- Data loading and streaming allow large volumes of data to be ingested.
- Distributed services
- Deployment of user-defined services in clusters.
- Machine Learning (Machine Learning)
- Pre-processing (extraction and standardization)
- Classification algorithms
- Regression algorithms
- Recommendation algorithms
- Clustering algorithms
- Integration with other technologies
- Spring data
- TensorFlow
- Spark
- Kafka
- Camel
- JMS
- MQTT
- Storm
- Flink
- Flume Sink
- ZeroMQ
- RocketMQ
- …
Memory storage
The main advantage of Ignite over other solutions is that it directly uses the system’s RAM to store and process data, making it one of the most efficient platforms available today.
Some facts about RAM and SSD/NVMe disks:
- Typical RAM transfer rate is between 2GB/s-25GB/s, while SSDs/NVMe disks are between 200MB/s-4GB/s for sequential reading/writing.
- The latencies of random reading/writing in RAM are of the order of nanoseconds, while in SSD/NVMe disks they are of the order of microseconds.
Considering this data, we can get an idea of the incredible performance obtained by directly using the RAM to store and process data.
Another advantage of using the system’s RAM directly is that it is not affected by the JVM’s GC (garbage collector) breaks.
But if we store the data in RAM, what happens if the system crashes?
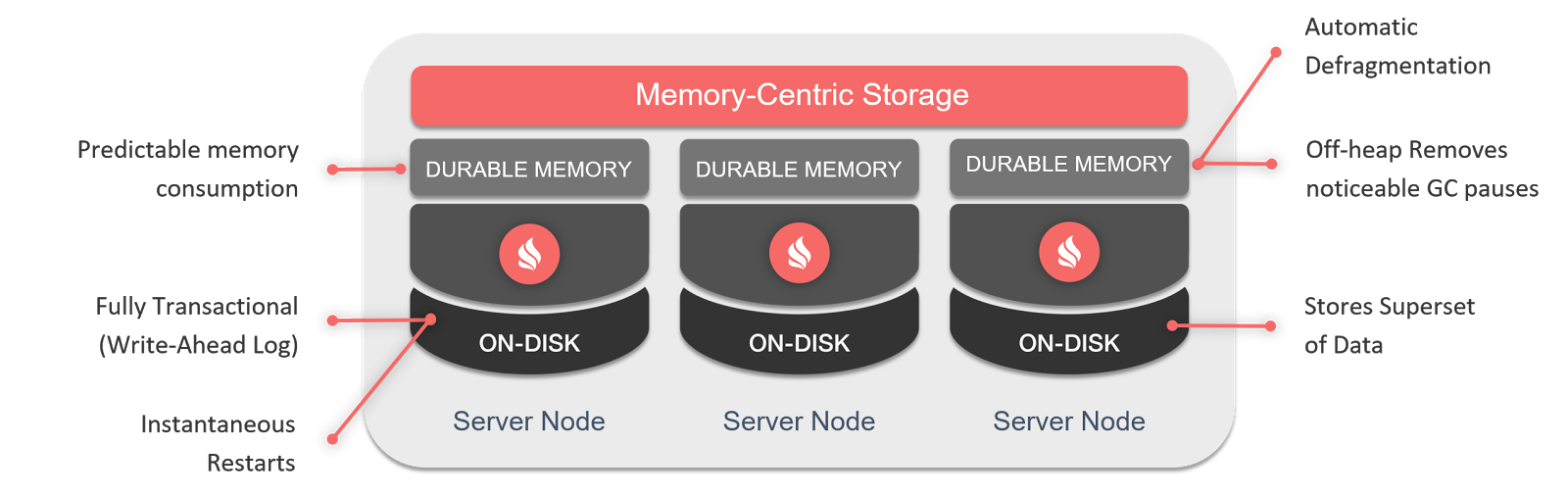
Ignite implements Durable Memory which completely guarantees the consistency and persistence of data in case of a partial/complete failure of the cluster and, of course, that the cluster is fully operational, without the need of data preloading after a restart.
The Ignite memory-centric platform is based on a durable memory architecture that allows storing and processing data and indexes both in memory and on disk when the Ignite Native Persistence feature is enabled. The durable memory architecture helps achieve in-memory performance with the durability of disk using all the available resources of the cluster.
Collocated computation
Ignite, allows you to send light calculations only to the nodes that contain the data, that is to say, place calculations with data. As a result, Ignite scales better and minimizes data movement, unlike most traditional databases, which operate on a client-server basis, meaning that data must be brought to the client side for processing, requiring a great deal of data movement from servers to clients and are generally not scalable.
Take a look to the post about the benefits of collocated computation.
ACID database integrity
The data stored in Ignite complies with ACID (Atomicity, Cconsistency, Isolation and Durability) both in memory and on disk, meaning that Ignite is a very consistent system.
Ignite transactions run through the network and can be distributed among multiple servers.
How do I start working with Apache Ignite or GridGain?
Let’s see how simple it is to incorporate Apache Ignite or GridGain into a Java application with maven. You can find more examples at Apache Ignite examples.
Other languages
Ignite provides implementations for other programming languages like java, C++, C#, Pyphon, node.js, so integrating it into your applications will not be expensive.
Hybrid architectures
It allows applications designed in the different supported languages to communicate with each other using the same technology: Ignite.
The configuration is quite simple. You’ll need to:
Add the dependency
ignite-core- mandatory - andignite-spring- since we’re going to use a configuration via spring - in your application’s pom.xml. You can use Apache Ignite or GridGain dependencies.Apache Ignite dependencies:
<dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-core</artifactId> <version>${ignite.version}</version> </dependency> <!-- optional, spring configuration --> <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-spring</artifactId> <version>${ignite.version}</version> </dependency>GridGain dependencies:
<dependency> <groupId>org.gridgain</groupId> <artifactId>ignite-core</artifactId> <version>${gridgain.version}</version> </dependency> <!-- optional, spring configuration --> <dependency> <groupId>org.gridgain</groupId> <artifactId>ignite-spring</artifactId> <version>${gridgain.version}</version> </dependency>
Create a spring file configured for Apache Ignite, and call it, for example,
ignite-config.xml.Minimum configuration of an Ignite node:
- Instance name (
gridName)[2] - Node type (
clientMode)[3] - Work directory (
workDirectory)[4] - Discovery mechanism (
discoverySpi)[5]
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="a-ignite-config" class="org.apache.ignite.configuration.IgniteConfiguration"> <property name="gridName" value="an-ignite-grid" /> <property name="clientMode" value="false" /> <property name="workDirectory" value="/opt/ignite/work" /> <property name="discoverySpi"> <bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"> <property name="localPort" value="45500" /> <property name="localPortRange" value="10" /> <property name="ipFinder"> <bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder"> <property name="shared" value="true"/> </bean> </property> </bean> </property> </bean> </beans>- Instance name (
Configuration
Note that this is a minimal configuration with local discovery through TCP.
Check out the official documentation to explore all available options (other discovery mechanisms, persistence, threads, logger, etc).
The configuration can also be created programmatically, although personally, I recommend the use of the spring file since it allows us to use different configurations depending on the execution environment, for example, to change the discovery mechanism (discoverySpi), without having to modify the binaries of our application.
- Create an Ignite instance to access its API.
Ignite ignite = Ignition.start("ignite-config.xml"); [...] // gets or creates a cache with default configuration IgniteCache cache = ignite.getOrCreateCache("my-cache"); cache.put(theKey, theValue);
Conclusions
Ignite is a powerful tool that can be extremely useful if you need to create escalable applications with high fault tolerance.
It offers a broad range of services, which will allow you to, among other things:
- Store data in key-value mode until it is exploited and analyzed using SQL/Lucene and/or ML.
- Create exclusive accesses to the resources (Locks, Semaphores) in the cluster.
- Efficiently ingest data by taking advantage of factory provided implementations or by creating your own.
- Use queues and topics to establish communications and/or distribute the computational load efficiently among services and applications.
- Enhanced management, monitoring and security for mission-critical production environments with GridGain®.
Ignite could certainly be considered as the “all-in-one “ of distributed computing.
Frequently Asked Questions
Can I have different Ignite instances running on the same JVM?
Yes. In fact, this feature is very interesting if we decide to implement an architecture formed by different Ignite clusters to split workloads, along with applications/services that need to access several clusters at once.
- Architecture with a single Ignite cluster:
- Architecture with several Ignite clusters to avoid a possible negative impact on performance, for example, so that the database is not affected by analytical processes that normally have a high CPU consumption:
In this sense, Ignite does not impose any restrictions, you can even have multiple instances in server mode grouped in different clusters running on the same JVM (Java Vvirtual Machine).
Other FAQs answered by the Apache Ignite team.
- 1.The Lucene search engine provided by Ignite supports textual searches. ↩
- 2.Name under which the Ignite instance will be registered with the local JVM. ↩
- 3.Mode in which the Ignite instance is started (client, server). ↩
- 4.Directory in the Ignite will store the needed artifacts. It must be unique per Ignite instance. ↩
- 5.Mechanism used to register/group/discover nodes that will be part of the same cluster (TCP, UDP, kubernetes, Amazon S3...). ↩