What is collocated computation? Why should you consider it when you want to design a scalable system with optimal performance?
Usually, when we design a scalable system we do so mainly for two reasons:
- To optimize performance, that is, to control our system’s growth and distribute the computational load among the different nodes that make up the cluster.
- To get high availability, that is, to control our system’s growth in order to replicate services, so if one fails another will take over to continue providing service.
In this article, we are going to focus on the first point: how to optimize performance by distributing computational load, particularly in a distributed database.
We will also see a small example applying collocated computation to data received from weather stations/beacons.
What is collocated computation?
Collocated computation consists of sending calculations only to the nodes of a cluster containing the data, i.e. placing calculations with data. As a result, the system will be able to scale better, and data movement will be minimized.
To achieve this, it is essential that data partitioning is done correctly.
Data partitioning
The database is usually a bottleneck in terms of performance, for instance, when we want to do complex searches on huge data sets.
Imagine you have a database with billions of records. Unless you have a very powerful computer, the usual thing to do is to create a cluster with N small computers (nodes) and partition the data so that each node contains a subset of the data, in order to improve the performance of the database queries and essentially the total system’s performance.
Obviously, it is not the same to search in a set containing 1 million elements as in one containing 1 billion.
How is it done?
When we have a data cluster, each node is assigned a series of partitions. For example, suppose the total number of data partitions is 10 (1-10) and our data cluster consists of 2 nodes. The assignment could look like this:
- Node 1 will own partitions: 2,3,8,9,10
- Node 2 will own partitions: 1,4,5,6,7
In data partitioning there are two key concepts for placing data in the different nodes of the database cluster:
- the affinity key, is an attribute that must be part of the data to be stored, normally of the primary key. The partition in which to store the data will be calculated from this key.
- the affinity function calculates the partition in which to store the data from the affinity key and thus the node in which the data will be stored. It is normally an internal function of your database manager and must be immutable in time.
Internal process of selecting the node in which to store data (collocated storage):
Partitioning local indexes
This is basically the same concept as data partitioning but applied to local indexes stored in a data cluster node. It will allow us to “mount” each partition of the local index on a different hard disk which will further increase the performance of our database.
Collocate the queries
The partitioning of data and indexes is important, but collocate the queries is even more relevant. This is crucial when we have more than one data node as it significantly reduces the resource consumption of the whole system.
What does “collocate the queries” mean?
It means to make the queries go only to the nodes that could potentially contain the data we are looking for.
How is it done?
Using the affinity key as a filter in the database queries. This filter is usually called the affinity condition.
As we have mentioned before, “the affinity key is an attribute that must be part of the data to be stored”, therefore, we can introduce that condition in the database query.
For instance, if we assume that the affinity key in our table is the country code (COUNTRY_CODE), to search for data in Spain (ES) or Portugal (PT), we would make the following query:
SELECT *
FROM MY_TABLE
WHERE
-- this is the affinity condition
COUNTRY_CODE IN ['ES', 'PT']
-- other conditions
AND SOME_FIELD = 'SOMETHING'Internally the database manager will extract the partitions from the query using the affinity function, and send the query only to the node(s) that may contain the data we want to find, i.e. those that own the partitions extracted from the affinity condition.
The number of nodes to which the placed query will be sent will always fall between 1 and the number of values for the affinity key used in the query.
Internal process of selecting the nodes that contain data for the collocated query:
If we extrapolate this example to a data cluster consisting, for example, of 200 nodes, our collocated query will only be sent to a maximum of 2 nodes, instead of the 200 that make up the cluster. Imagine the performance improvement!
A very visual example - Weather stations
Imagine that we have a database containing weather information from stations/beacons spread all over the globe, a number that would probably be in the order of hundreds of millions of daily records.
Our data cluster will be divided, for example, into 128 nodes that will store all the Earth’s weather information.
The affinity key
One of the key points when we’re dealing with partitioned datasets in a distributed database is that the affinity key is defined correctly.
In this example, as there may be stations/beacons at any point on the globe, we are going to divide the Earth’s map into cells that will represent our affinity keys, for example, in a 32x32 grid (1024 cells).
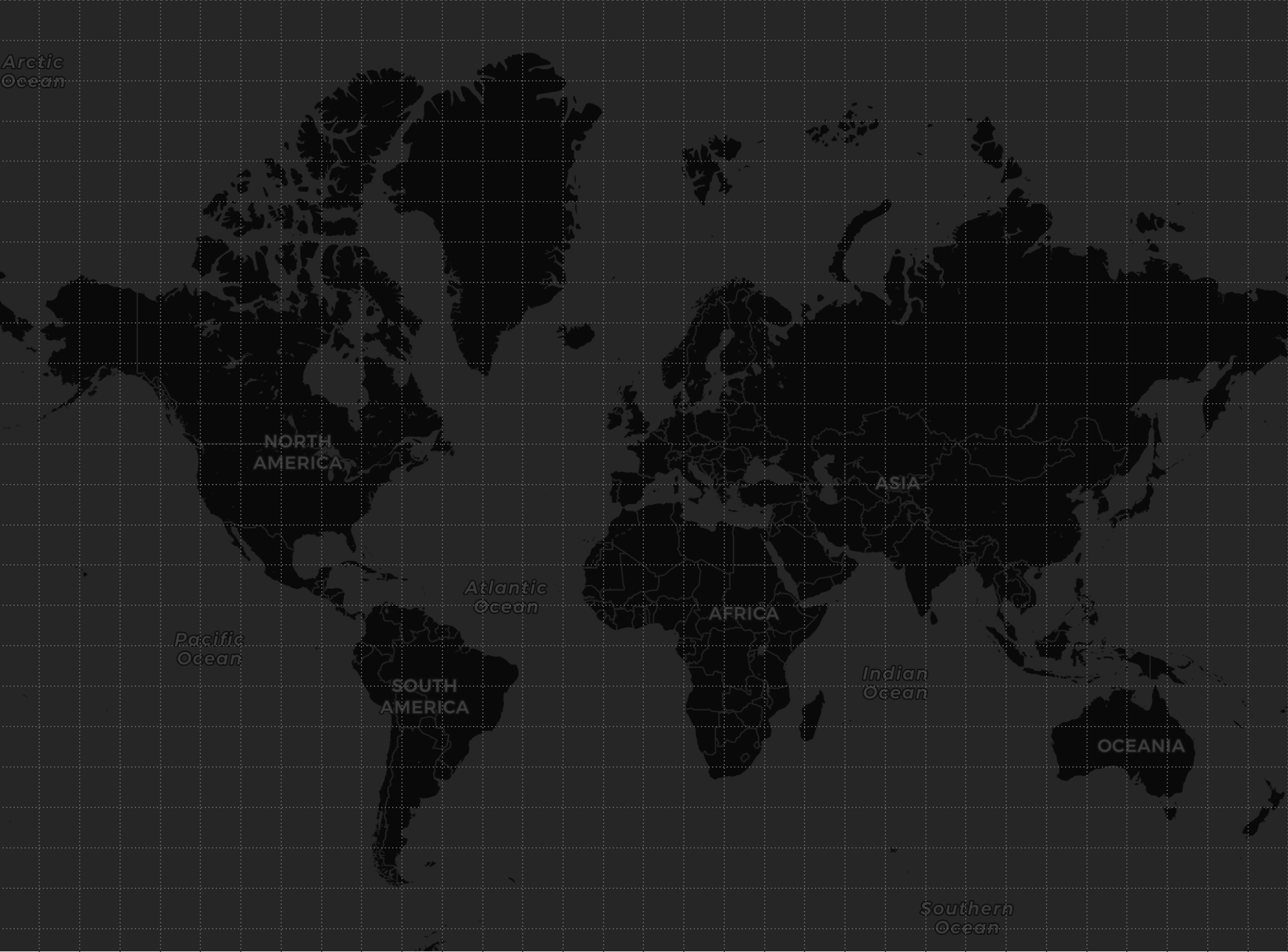
Each station/beacon has a geospatial position and a cell (TILE) on the map.
Once we receive the information from the station/beacon, we will use its geo-position to calculate the cell (affinity key) in which it is located. The database manager will use the affinity key and the affinity function to calculate the partition corresponding to the cell and store this information in the node that owns that partition.
The query
In this case, we would like to know where in Europe it is going to rain, so we will create a search area which we will call, for example, GEO_SHAPE_FILTER:
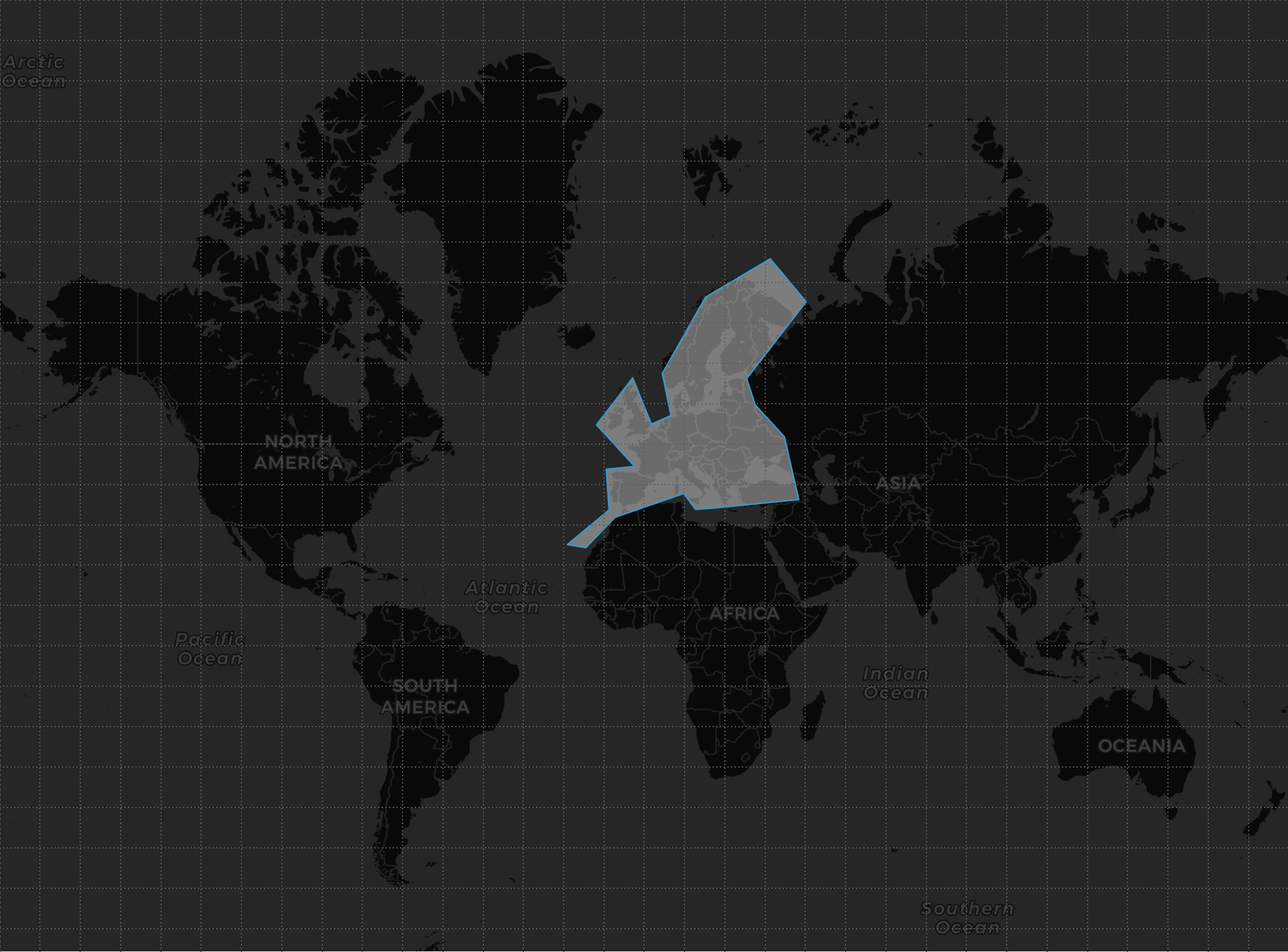
Collocate the query
We are only interested in receiving data from stations/beacons located within the search area, so the first thing we must do to collocate the query in the nodes that contain data is to calculate the cells that contain the search area, it will be a vector that we will call, for example, TILES_VECTOR:
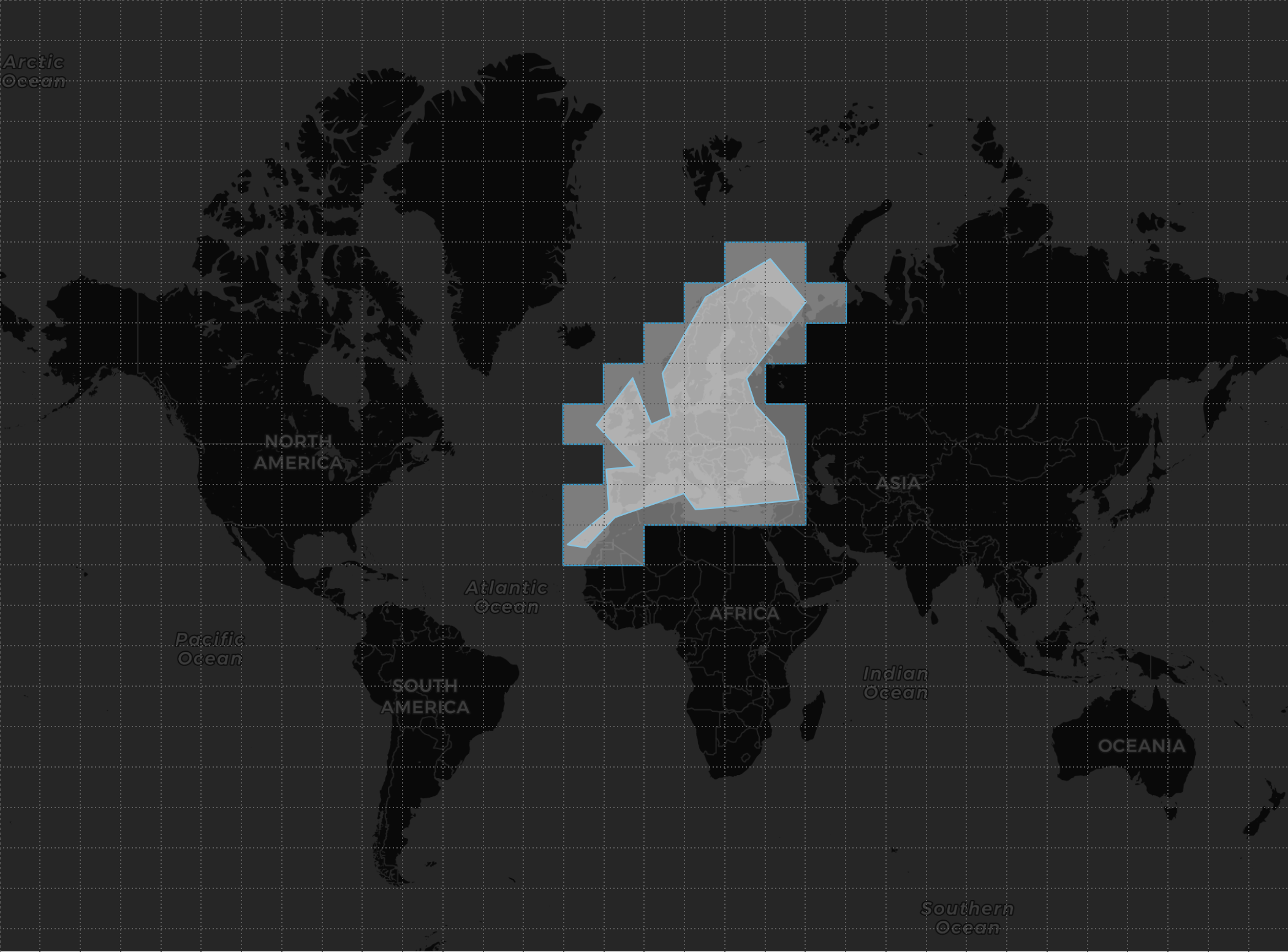
To place the query, simply enter the affinity condition, in this case, that the station/beacon cell (TILE) is contained in our TILES_VECTOR vector.
SELECT *
FROM WEATHER_STATION_SNAPSHOTS
WHERE
-- this is the affinity condition
TILE IN TILES_VECTOR
-- this is the range weather condition
AND PRESSURE BETWEEN (P1, P2)
AND HUMIDITY BETWEEN (H1, H2)
AND WIND BETWEEN (W1, W2)
-- this is the range snapshot-timestamp condition
AND SNAPSHOT_TS BETWEEN (T1, T2)
-- this is the intersect geo-condition
AND POSITION && GEO_SHAPE_FILTERThe database manager, applying the affinity function, calculates a series of partitions for the cells of the TILES_VECTOR vector provided by the query; in our example, the database manager calculated that the query should only be sent to 4 nodes -which are the ones that contain data for those partitions- out of the 128 that make up the cluster:
- Selected nodes for the collocated query: 1 2 3 4 .
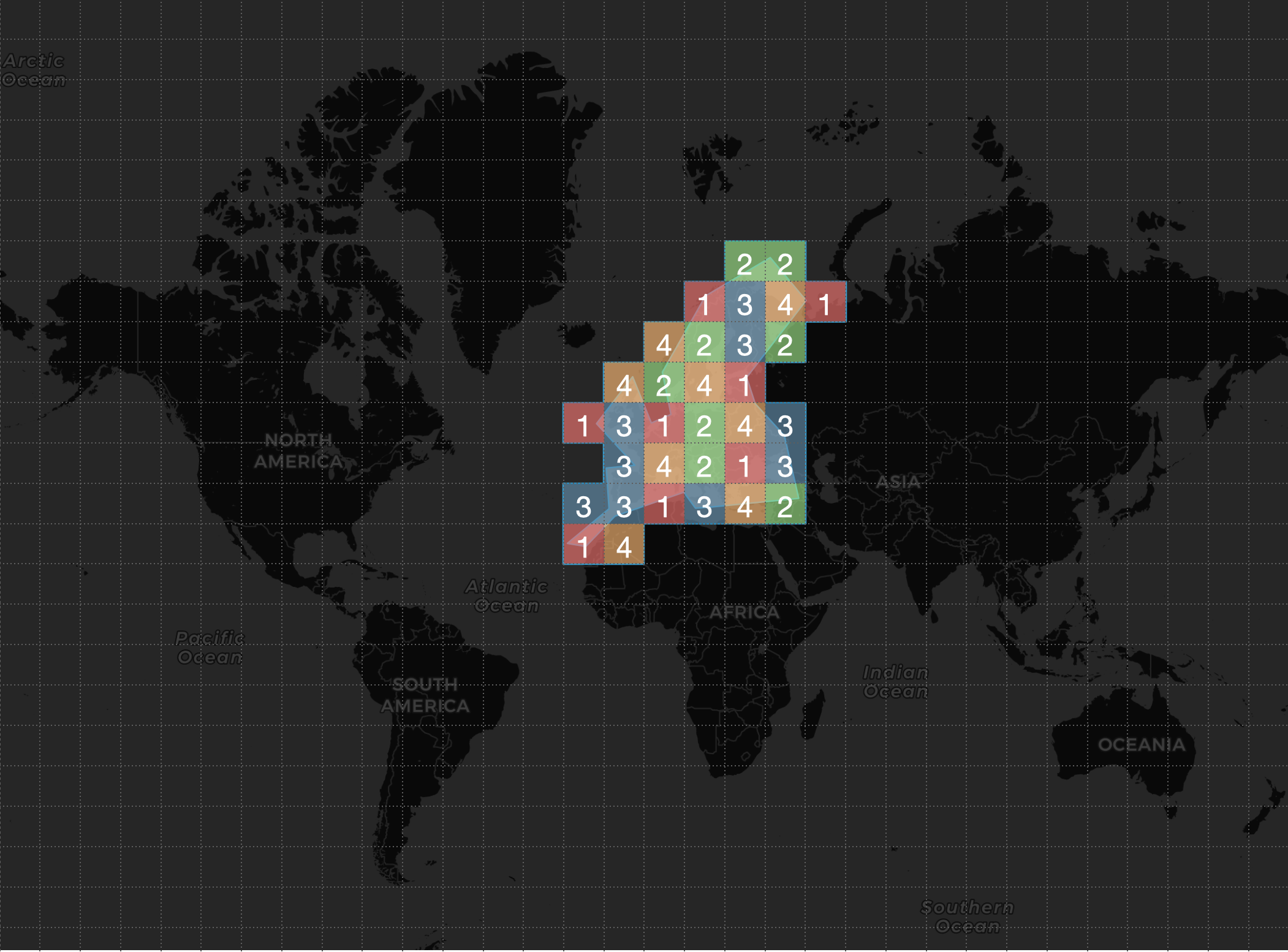
Conclusions
Understanding collocated computation and correctly defining both affinity keys and query collocation is crucial when working with billions of records in distributed clustered databases. Do not forget:
- Choose a platform that supports collocated computation such as Apache Ignite or GridGain.
- Study your data model to correctly choose the affinity key that will be used to collocate the data and collocate the queries.
- Use query collocation whenever possible, to reduce resource consumption, and increase the performance of your system.
As a whole, collocated computation in a clustered and partitioned system offers the following advantages:
- It optimizes resource consumption because every piece of data is stored in a specific node of the cluster[1].
- Significantly improves data analysis performance because computations are carried out at specific nodes in the cluster.
- Increases overall system performance by minimizing data movement and avoiding unnecessary computations on nodes that have no data.
If you wish to go deeper into this topic, you can find detailed information in the documentation of advanced indexing for Apache Ignite and affinity collocation.
- 1.Some distributed computation platforms, such as Apache Ignite or GridGain, allow you to have partitioned data backups at other nodes in your cluster to ensure high fault tolerance. ↩