In previous posts we have already spoken of Apache Ignite and its capabilities as a distributed SQL/Lucene database.
This feature allows us to analyze information stored in our cluster in a simple way, using SQL and Lucene expressions. However, the standard functionality provided by Apache Ignite may not be sufficient in certain circumstances:
When you need immediate availability of the cluster when using Lucene or geospatial indexing with native persistence.
- The standard Lucene and geospatial indexes provided by Apache Ignite are not available after a reboot, as they do not support native disk persistence. This feature forces a manual re-indexing, with the consequent delay in the availability of the database cluster.
When you need to perform complex searches.
The standard Lucene indexing module provided by Apache Ignite only supports textual searches.
Performing complex searches using only standard SQL can be an almost impossible task, with a huge impact on performance.
For example, think about how to search for geo-positioned tweets written from the U.S. and Europe, between two dates containing the #happy or #feliz hashtags, in a database with billions of entries, with a single query and that the answer is available in milliseconds.
When you need to change your database schema.
- These changes can only be made manually and the creation of the indexes is atomic, i.e., the indexes must be created one by one and for each index created a complete scan of the data is performed. Think of a database with billions of records and the performance penalty that goes with it.
To remove these limitations, at Hawkore we have developed a set of modules that extend the search, indexing, persistence, and schema mutation capabilities of Apache Ignite’s distributed SQL/Lucene database.
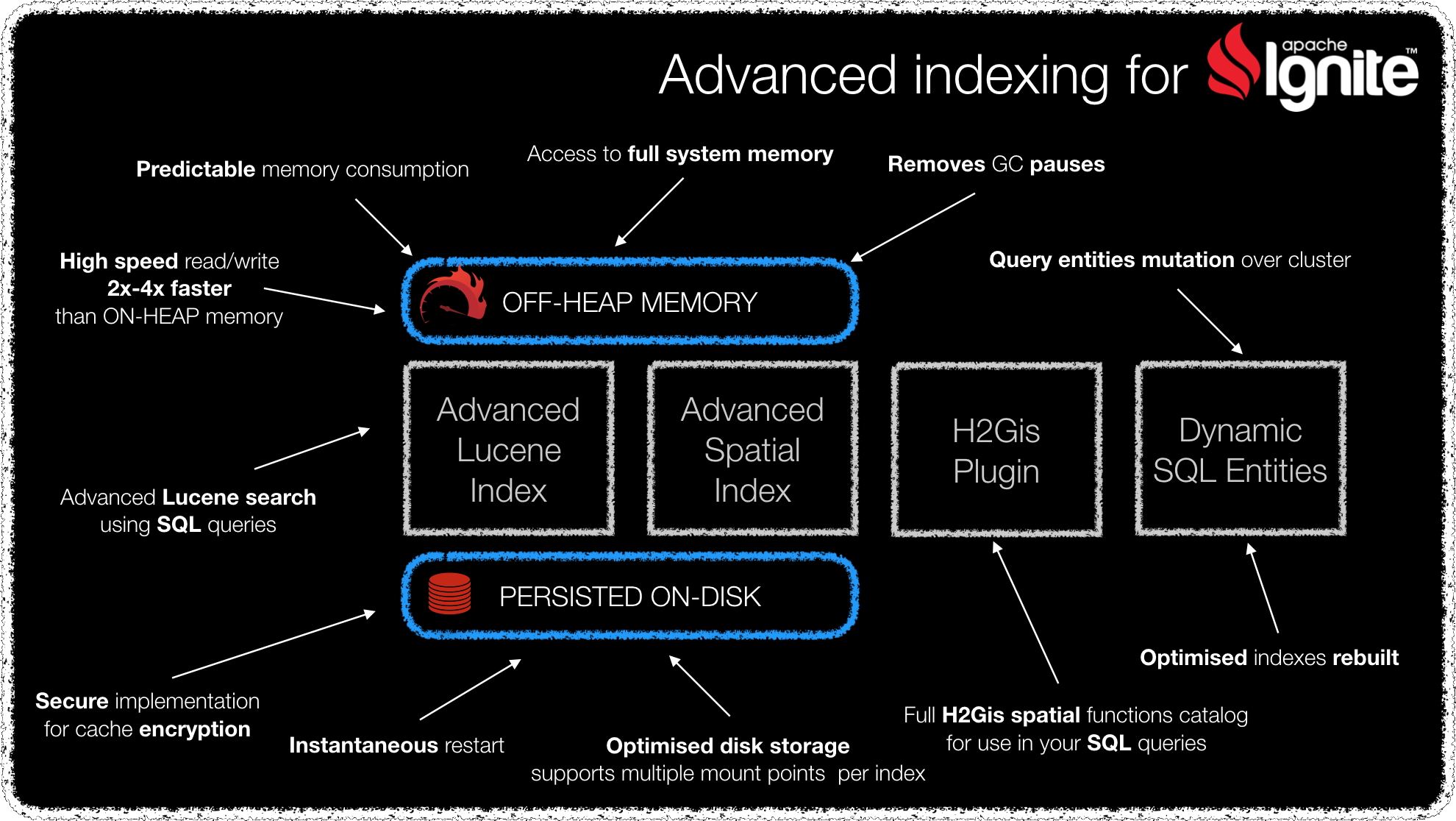
Instant availability of a reliable database cluster after a reboot. Our Apache Lucene and Geospatial indexes support optimized disk persistence, without losing the high performance of the distributed in-memory computing layer.
Combines the SQL capabilities of Apache Ignite with extended Apache Lucene. Yes, you read it well! You can do a SQL query using Lucene filtering expressions that can be as complex as you want, with a response time of milliseconds.
You can modify the Apache Ignite database schemas (QueryEntity) at runtime without needing a reboot and without loss of information:
- Add new fields (indexed or not) to your entities at runtime.
- Optimized index reconstruction process which automatically detects if re-indexing is necessary, and can do it simultaneously for all new indexes with only one background data scan.
Main features of the extended Lucene index
- Supports disk persistence, without losing the performance of the in-memory computing layer, allowing your data cluster to be immediately available.
- Secure implementation for Apache Ignite EncryptionSpi since the Lucene index does not store the cache entry value.
- Supports updating and rebuilding of indexes at runtime.
- Supports
TextQuerywith Lucene’s advanced search expressions. - Supports the syntax of the classic Lucene query analyzer in the Lucene search expression.
- Full-text search (language recognition analysis, wildcard, diffuse, regular expression).
- Boolean search (and, or, not).
- Sorting by relevance, column value, and distance.
- Geospatial indexing (points, lines, polygons, and their collections).
- Geospatial transformations (bounding box, buffer, centroid, convex hull, union, difference, and intersection).
- Geospatial operations (intersection, contains, is in).
- Bitemporal search (valid time and transaction time).
- Paging across cluster, even with ordered searches.
- Integration with Spring Data 2.0 SpEL.
You want to know how it works?
Sign up at www.hawkore.com, access all the documentation with practical examples and try it out for Free!