In previous articles, we have talked about the high degree of productivity of Mule ESB and of the distributed computing capabilities of GridGain.
What if you could bring together the best of both technologies?
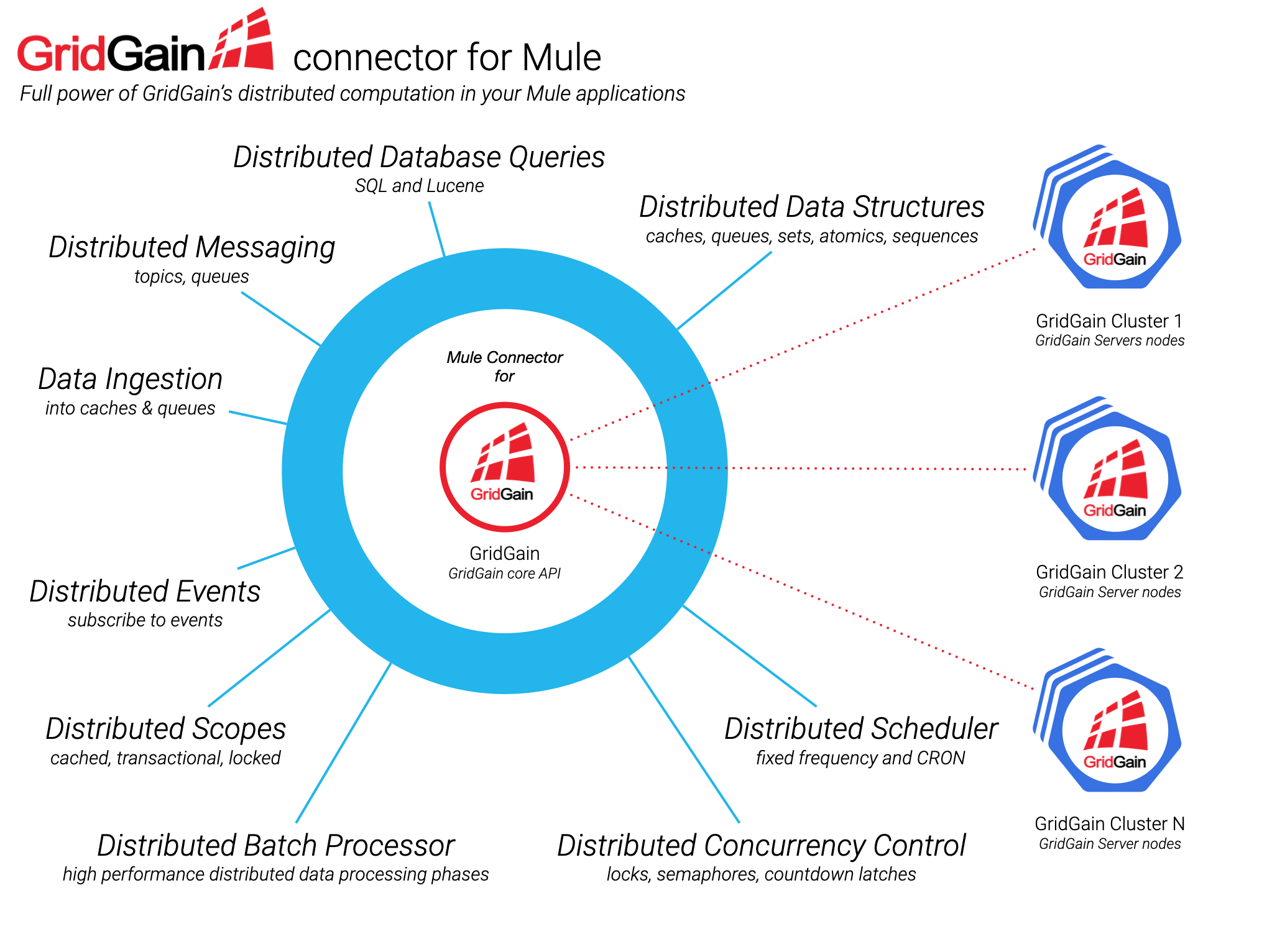
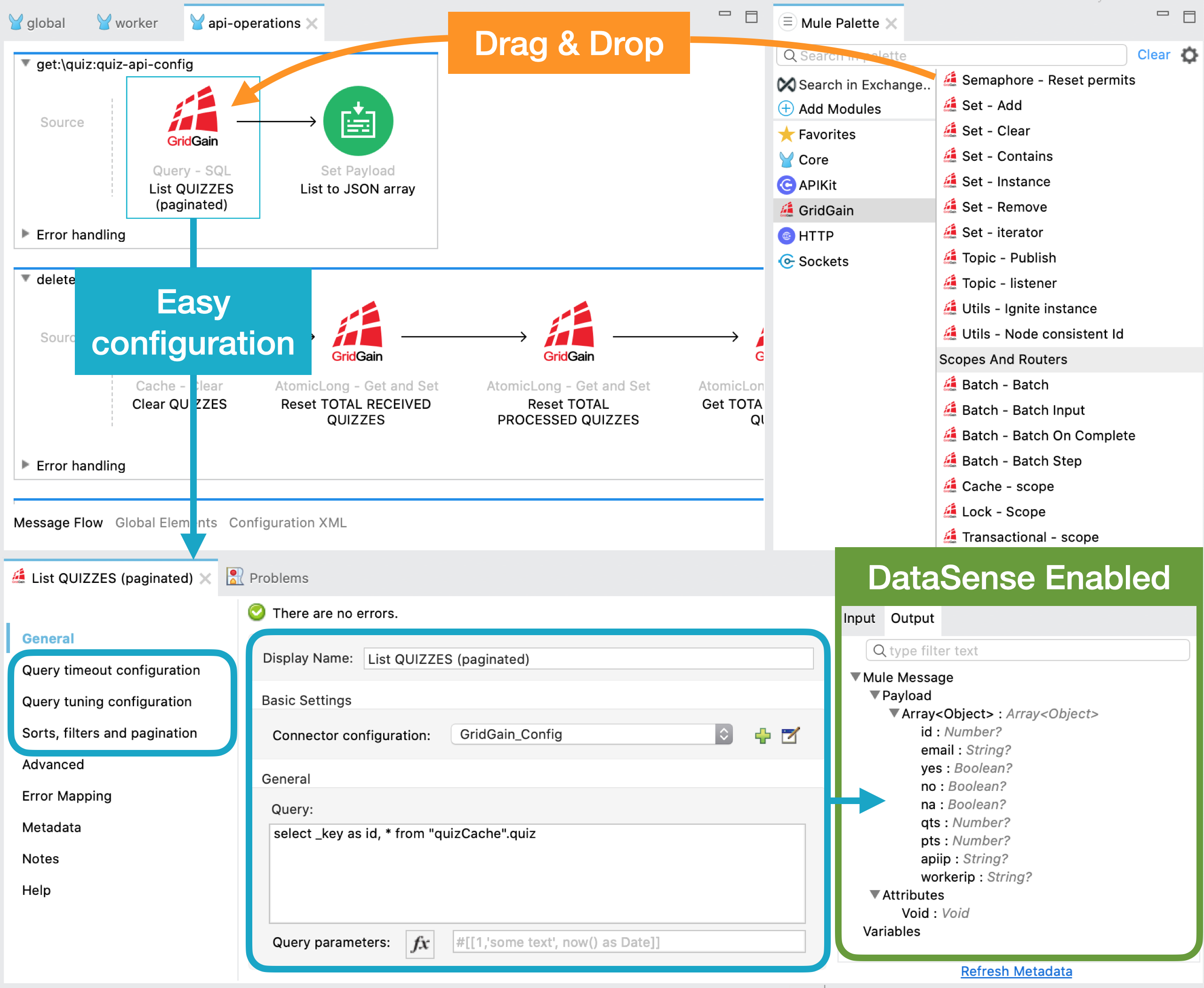
With our GridGain connector for Mule you can use the full power of GridGain’s distributed computation in your Mule applications, in the purest Anypoint Studio’s Drag & Drop style, significantly reducing development time.
All this, thanks to the easy configuration of operations and the automatic resolution of input and output message structures while you’re designing - DataSense.
Plus, you can use it with both Mule Community Edition - kernel - and Mule Enterprise Edition (on-premise and CloudHub).
Features
The GridGain connector for Mule offers your Mule applications all the power of GridGain:
- Distributed concurrency control structures - locks, semaphores, and countdown latch.
- Distributed atomic data structures - long, references, sequences, and stamps.
- Distributed high-level data structures - sets, topics, queues, and caches.
- Data queries using SQL and Lucene.
- Transactional, cached, and of exclusive access (locks) distributed Scopes.
- Distributed Task scheduler.
- Distributed Batch jobs.
Typical use cases
- Synchronization of clustered operations using GridGain’s concurrency control tools.
- Scaling your processes (load balancing for distributed clustering) with the help of GridGain’s distributed data structures.
- Query and analyze data stored in your GridGain cluster using SQL or Lucene.
- Clustered cache of the execution result of a chain of Mule processors, which could eventually be heavy, to improve performance.
- Design and execute distributed batch processes.
- Schedule the execution of clustered processes.
- Massive Data ingestion.
Would you like to see an example?
Check out the article about Distributed computation with Mule and Kubernetes.
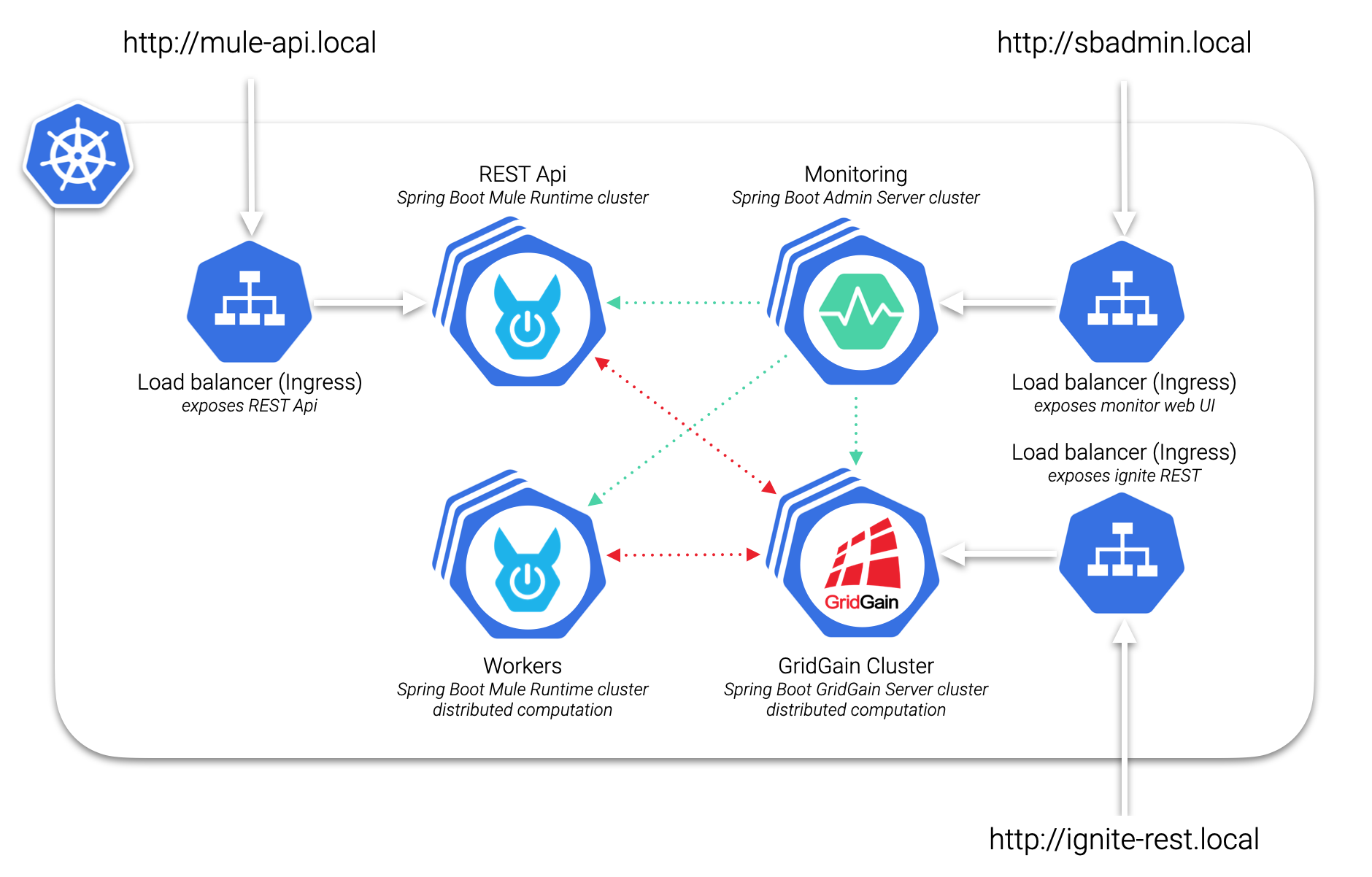
You can find more examples in our GitHub repository.