En anteriores posts ya os hemos hablado de Apache Ignite y sus capacidades como base de datos SQL/Lucene distribuida.
Esta característica nos permite analizar la información almacenada en nuestro clúster, de forma sencilla, usando SQL y expresiones Lucene. No obstante, la funcionalidad que ofrece Apache Ignite de fábrica puede no ser suficiente en determinadas circunstancias:
Cuando necesites disponibilidad inmediata del clúster si usas indexado Lucene o geo-espacial con persistencia nativa.
- Los índices Lucene y geo-espaciales que proporciona Apache Ignite de fábrica no están disponibles tras un reinicio, ya que no soportan persistencia nativa en disco. Esta característica obliga a hacer un re-indexado manual, con la consiguiente demora en la disponibilidad del clúster de base de datos.
Cuando quieras realizar búsquedas complejas.
El módulo de indexación Lucene que proporciona Apache Ignite de fábrica sólo soporta búsquedas textuales.
Realizar búsquedas complejas usando únicamente SQL estándar puede llegar a ser una tarea casi imposible, con un alto impacto en el rendimiento.
Por ejemplo, piensa en cómo buscar tweets geo-posicionados escritos desde U.S.A. y Europa, entre dos fechas que contengan los hashtags #happy o #feliz, en una base de datos con miles de millones de entradas, con una única consulta y que la respuesta esté disponible en milisegundos.
Cuando necesites cambiar los esquemas de tu base de datos.
- Estos cambios sólo se pueden realizar de forma manual y la creación de los índices es atómica, es decir, los índices se deben crear uno a uno y por cada índice creado se realiza un escaneo completo de los datos. Piensa en una base de datos con miles de millones de registros y la penalización de rendimiento que ello supone.
Para eliminar estas limitaciones, en Hawkore hemos desarrollado un conjunto de módulos que amplían las capacidades búsqueda, indexación, persistencia y mutación de esquemas de la base de datos SQL/Lucene distribuida de Apache Ignite.
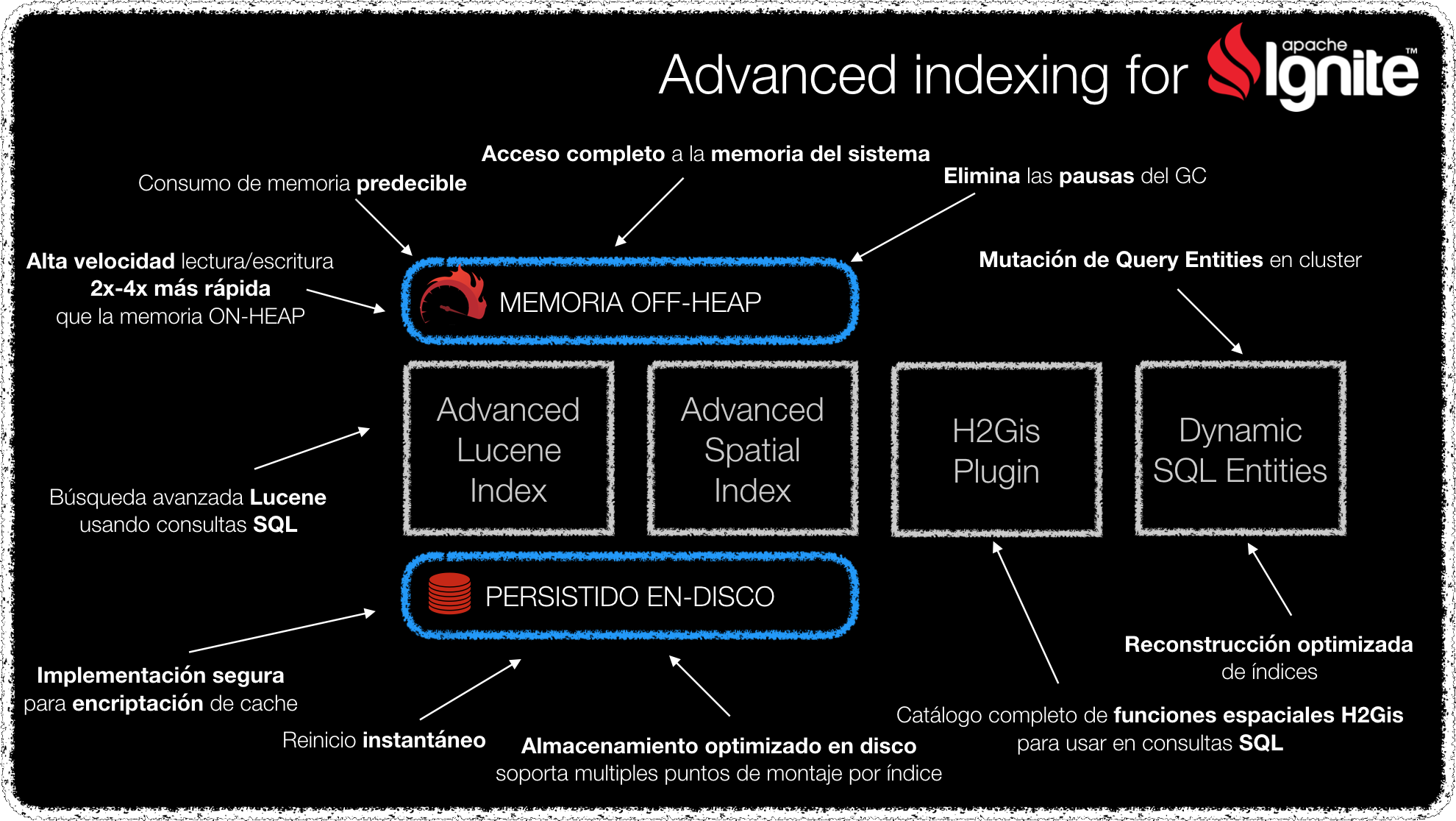
Dispón de forma instantánea de un clúster de base de datos fiable tras un reinicio. Nuestros índices de Apache Lucene y geo-espaciales soportan persistencia en disco optimizada, sin perder el alto rendimiento de la capa de computación distribuida en memoria.
Combina las capacidades SQL de Apache Ignite con filtros extendidos de Apache Lucene. ¡Sí, como lo lees! Puedes hacer una consulta SQL usando expresiones Lucene de filtrado que puede ser tan compleja como quieras, con tiempos de respuesta del orden de milisegundos.
Puedes modificar los esquemas de base de datos (QueryEntity) de Apache Ignite en caliente sin necesidad de reinicio y sin pérdida de información:
- Añade nuevos campos (indexados o no) en caliente a tus entidades.
- Proceso de reconstrucción de índices optimizado, que detecta automáticamente si es necesario re-indexar, y es capaz de hacerlo simultáneamente para todos los nuevos índices con un sólo escaneo de datos en segundo plano.
Principales características del índice Lucene extendido
- Soporta persistencia del disco, sin perder el rendimiento de la capa de computación en memoria, lo que permite que tu clúster de datos esté disponible inmediatamente.
- Implementación segura para Apache Ignite EncryptionSpi ya que el índice Lucene no almacena el valor de la entrada de caché.
- Soporta actualización y reconstrucción de los índices en tiempo de ejecución.
- Soporta
TextQuerycon expresiones de búsqueda avanzada de Lucene. - Soporta la sintaxis del analizador de consultas clásico de Lucene en la expresión de búsqueda de Lucene.
- Búsqueda de texto completo (análisis con reconocimiento de idioma, comodín, difuso, expresión regular).
- Búsqueda booleana (y, o, no).
- Ordenación por relevancia, valor de columna y distancia.
- Indexación geo-espacial (puntos, líneas, polígonos y sus colecciones).
- Transformaciones geo-espaciales (cuadro delimitador, búfer, centroide, envolvente convexa, unión, diferencia e intersección).
- Operaciones geo-espaciales (intersección, contiene y está dentro).
- Búsqueda bitemporal (duración válida y tiempo de transacción).
- Paginación en clúster, incluso con búsquedas ordenadas.
- Integración con Spring Data 2.0 SpEL.
¿Quieres ver cómo funciona?
Regístrate en www.hawkore.com, accede a toda la documentación con ejemplos prácticos y pruébalo ¡gratis!