¿Qué es la computación colocada? ¿Por qué debes tenerla en cuenta cuando quieras diseñar un sistema escalable con un rendimiento óptimo?
En general, cuando diseñamos un sistema escalable lo hacemos principalmente por dos motivos:
- Para optimizar el rendimiento, es decir, controlar el crecimiento de nuestro sistema para repartir la carga computacional entre los diferentes nodos que conforman el clúster.
- Para conseguir alta disponibilidad, es decir, controlar el crecimiento de nuestro sistema para replicar servicios, así, si uno falla otro se hará cargo de seguir dando servicio.
En este artículo, nos vamos a centrar en el primer punto, es decir, cómo optimizar el rendimiento repartiendo carga computacional, particularmente en una base de datos distribuida.
También veremos un pequeño ejemplo aplicando computación colocada a datos recibidos desde estaciones/balizas meteorológicas.
¿Qué es la computación colocada?
La computación colocada consiste en enviar cálculos únicamente a los nodos de un clúster que contienen los datos, es decir, colocar cálculos con datos. Como resultado, el sistema podrá escalar mejor y se minimizará el movimiento de datos.
Para ello es indispensable hacer un correcto particionamiento de los datos.
Particionamiento de los datos
La base de datos suele ser un cuello de botella en cuanto al rendimiento, por ejemplo, cuando queremos hacer búsquedas complejas en conjuntos de datos enormes.
Imagina que tienes una base de datos con miles de millones de registros. A no ser que dispongas de una computadora muy potente, lo habitual es crear un clúster con N pequeñas computadoras (nodos) y particionar los datos para que cada nodo contenga un subconjunto de estos, con el objetivo de mejorar el rendimiento de las consultas a la base de datos y en general el rendimiento total del sistema.
Como es obvio, no es lo mismo buscar en un conjunto que contenga 1 millón de elementos que en uno que contenga 1000 millones.
¿Cómo se hace?
Cuando tenemos un clúster de datos, a cada nodo se le asignan una serie de particiones. Por ejemplo, supongamos que el número total de particiones de datos es 10 (1-10) y nuestro clúster de datos está formado por 2 nodos, la asignación podría quedar así:
- El nodo 1 será propietario de las particiones: 2,3,8,9,10
- El nodo 2 será propietario de las particiones: 1,4,5,6,7
En el particionamiento de datos intervienen dos conceptos clave para colocar los datos en los diferentes nodos del clúster de base de datos:
- la clave de afinidad, es un atributo que debe formar del dato a almacenar, normalmente de la clave primaria. A partir de ella se calculará la partición en la que almacenar el dato.
- la función de afinidad calcula la partición en la que almacenar los datos a partir de la clave de afinidad y, por ende, el nodo en el que se almacenará el dato. Normalmente es una función interna de tu gestor de base de datos y debe ser inmutable en el tiempo.
Proceso interno de selección del nodo en el que almacenar el dato (almacenamiento colocado):
Particionamiento de índices locales
Básicamente es el mismo concepto que el particionamiento de datos, pero aplicado a los índices locales almacenados en un nodo del clúster de datos. Esto nos permitirá “montar” cada partición del índice local en un disco duro diferente lo que incrementará aún más el rendimiento de nuestra base de datos.
Colocar las consultas
Es importante particionar los datos y los índices, pero colocar las consultas es aún más relevante. Es crucial cuando tenemos más de un nodo de datos ya que reduce significativamente el consumo de recursos de todo el sistema.
¿Qué significa “colocar las consultas”?
Simplemente es hacer que la consultas vayan únicamente a los nodos que potencialmente podrían contener los datos que buscamos.
¿Cómo se hace?
Usando la clave de afinidad como filtro en las consultas a la base de datos. Este filtro se suele llamar condición de afinidad.
Como hemos comentado anteriormente, “la clave de afinidad es un atributo que debe formar parte del dato a almacenar”, por tanto, podemos introducir esa condición en la consulta a la base de datos.
Por ejemplo, si suponemos que la clave de afinidad de nuestra tabla es el código de país (COUNTRY_CODE), para buscar datos en España (ES) o Portugal (PT) haríamos la siguiente consulta:
SELECT *
FROM MY_TABLE
WHERE
-- esta es la condición de afinidad
COUNTRY_CODE IN ['ES', 'PT']
-- otras condiciones
AND SOME_FIELD = 'SOMETHING'Internamente el gestor de base de datos extraerá las particiones de la consulta usando la función de afinidad, y enviará la consulta únicamente al nodo(s) que puede(n) contener los datos que queremos encontrar, es decir, a aquellos que sean propietarios de las particiones extraídas de la condición de afinidad.
El número de nodos a los que se enviará la consulta colocada estará comprendido siempre entre 1 y el número de valores para la clave de afinidad usado en la consulta.
Proceso interno de selección de los nodos que contienen datos para la búsqueda colocada:
Si extrapolamos este ejemplo a un clúster de datos formado, por ejemplo, por 200 nodos, nuestra consulta colocada sólo se enviará a un máximo de 2 nodos, en lugar de a los 200 que conforman el clúster. ¡Imagina la mejora de rendimiento!
Un ejemplo muy visual - Estaciones meteorológicas
Imagina que tenemos una base de datos que contiene información meteorológica de estaciones/balizas repartidas por todo el globo terráqueo, este número podría ser del orden de cientos de millones de registros diarios.
Nuestro clúster de datos estará dividido, por ejemplo, en 128 nodos que almacenarán toda la información meteorológica de la Tierra.
La clave de afinidad
Uno de los puntos más importantes cuando tenemos conjuntos de datos particionados en una base distribuida es definir correctamente la clave de afinidad.
En este ejemplo, como potencialmente puede haber estaciones/balizas en cualquier punto del globo terráqueo, vamos a dividir el mapa terráqueo en celdas que representarán nuestras claves de afinidad, por ejemplo, en una rejilla de 32x32 (1024 celdas).
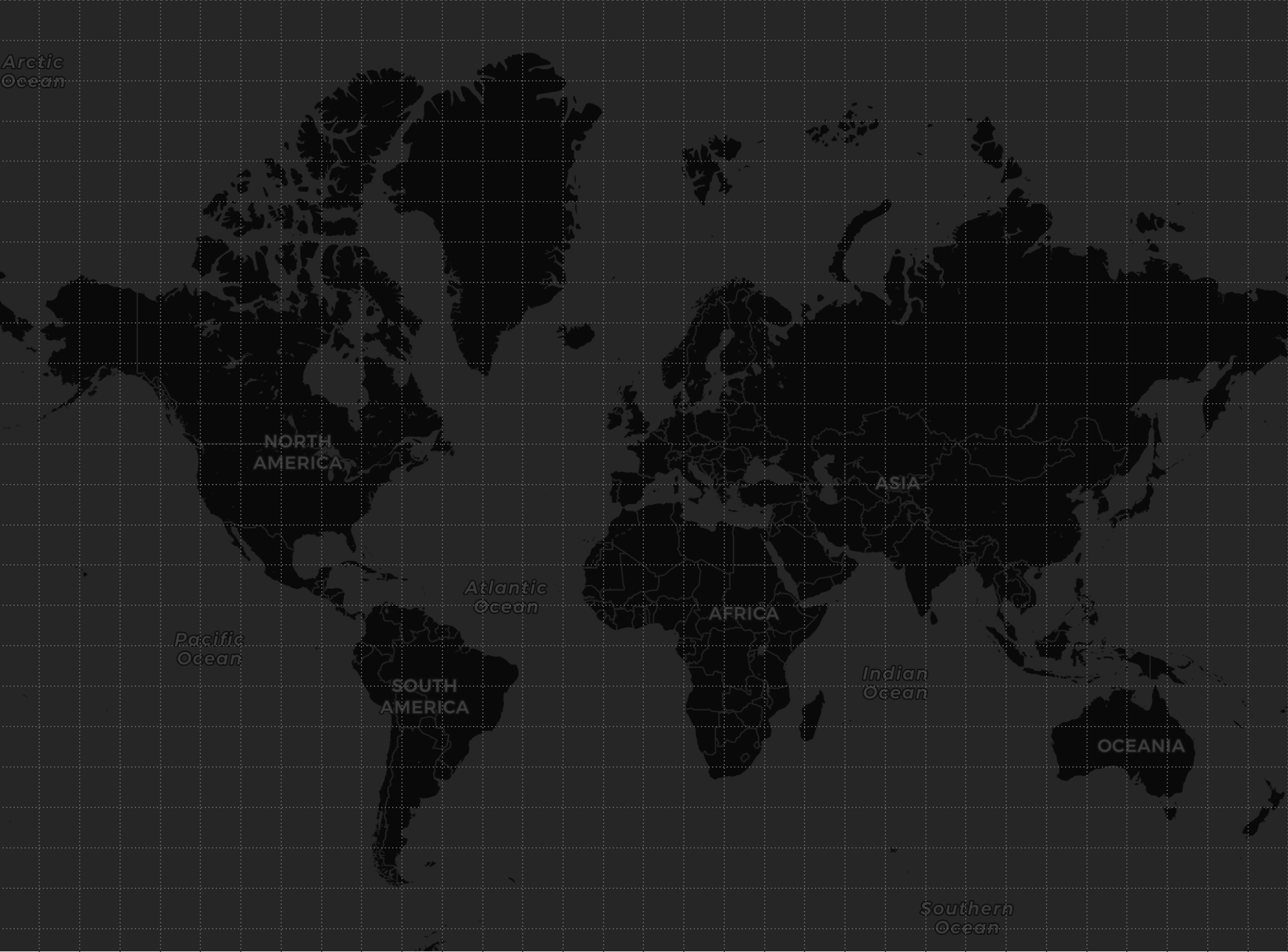
Cada estación/baliza tiene una posición geoespacial y estará en una celda (TILE) en el mapa.
Una vez recibida la información de la estación/baliza, a partir de su geo-posición calcularemos la celda (clave de afinidad) en la que está ubicada. El gestor de base de datos usará la clave de afinidad y la función de afinidad para calcular la partición correspondiente a la celda y almacenar esta información en el nodo propietario de dicha partición.
La consulta
En este caso, nos gustaría saber en que puntos de Europa va a llover, para ello crearemos un área de búsqueda al que llamaremos, por ejemplo, GEO_SHAPE_FILTER:
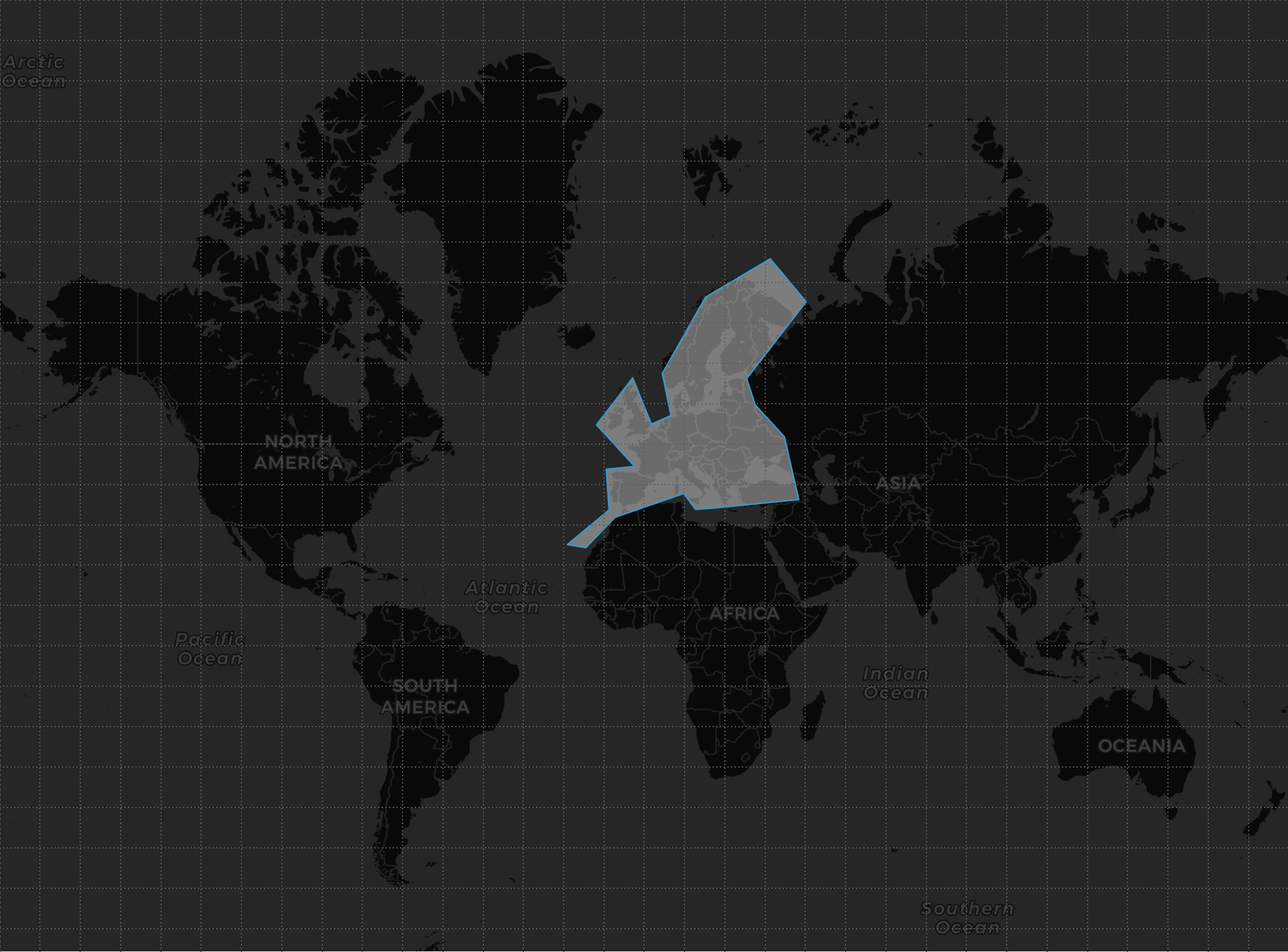
Colocar la consulta
Sólo nos interesa recibir datos de estaciones/balizas ubicadas dentro del área de búsqueda, por lo que lo primero que debemos hacer para colocar la consulta en los nodos que contienen datos es calcular las celdas que contienen al área de búsqueda, será un vector al que llamaremos, por ejemplo, TILES_VECTOR:
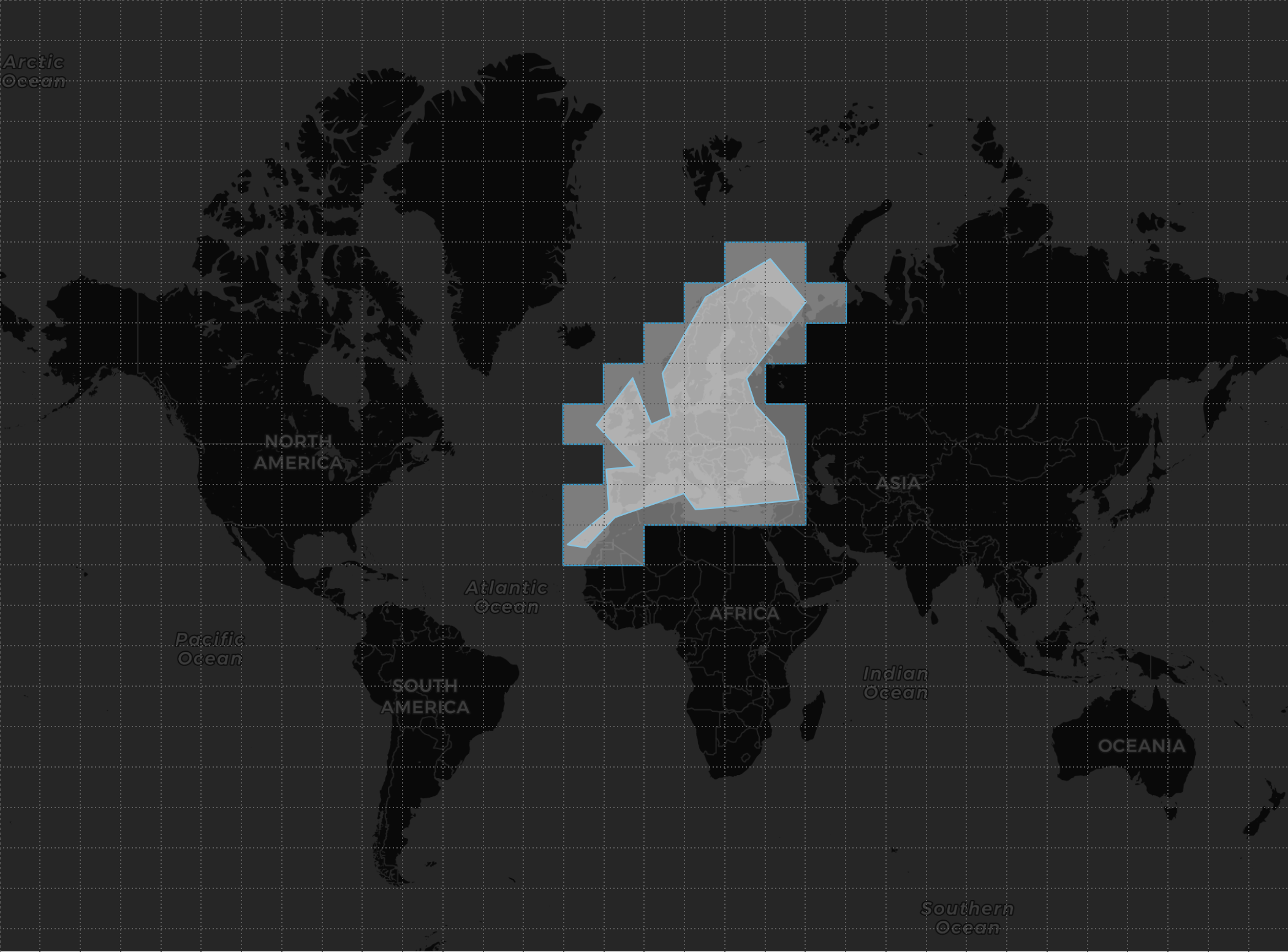
Para colocar la consulta, simplemente debemos introducir la condición de afinidad, en este caso, que la celda de la estación/baliza (TILE) esté contenida en nuestro vector TILES_VECTOR.
SELECT *
FROM WEATHER_STATION_SNAPSHOTS
WHERE
-- esta es la condición de afinidad
TILE IN TILES_VECTOR
-- esta es la condición de rango climatológico
AND PRESSURE BETWEEN (P1, P2)
AND HUMIDITY BETWEEN (H1, H2)
AND WIND BETWEEN (W1, W2)
-- esta es la condicion de rango de momento de captura
AND SNAPSHOT_TS BETWEEN (T1, T2)
-- esta es la condición de intersección geo-espacial
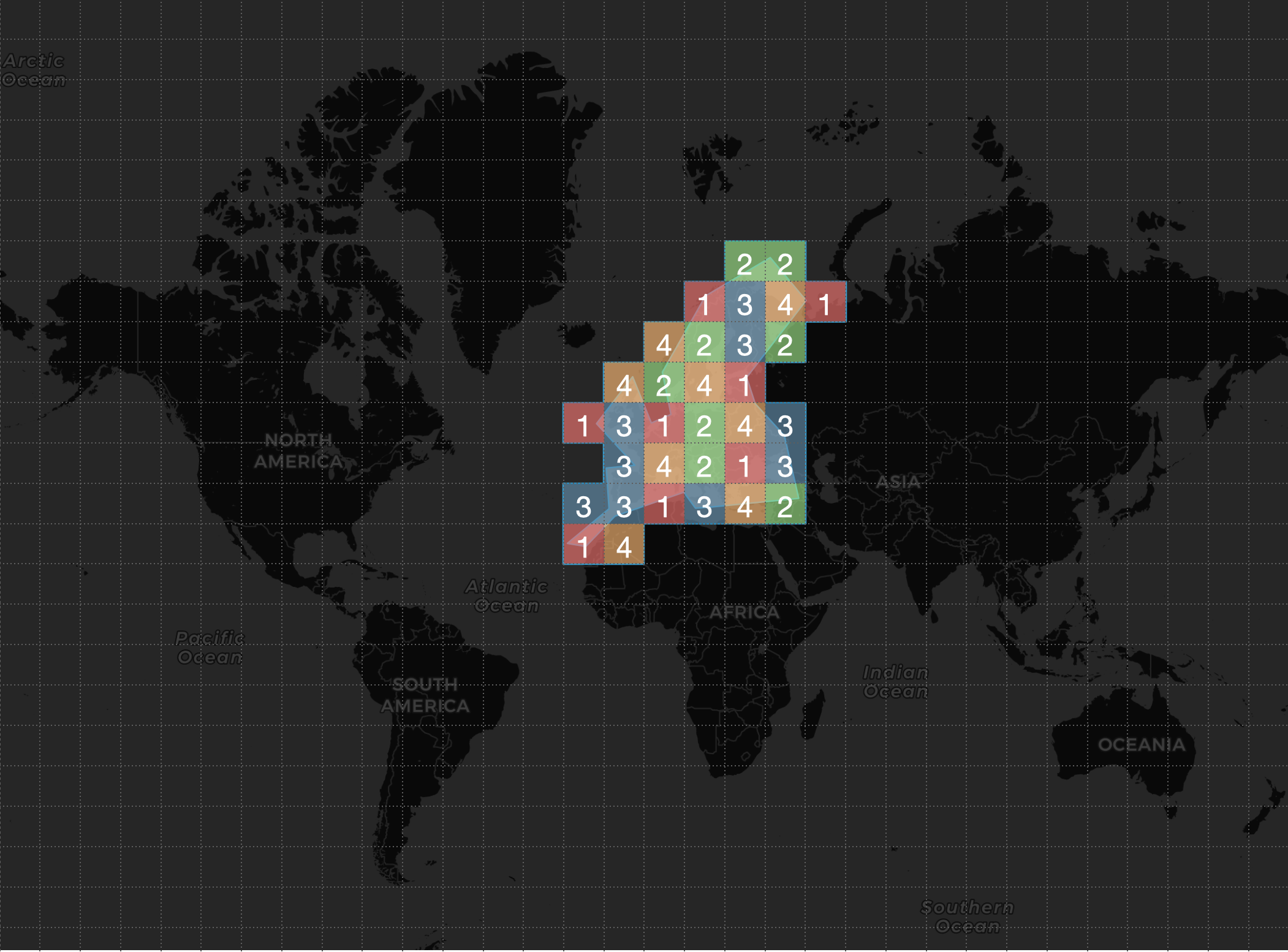
AND POSITION && GEO_SHAPE_FILTEREl gestor de base de datos, aplicando la función de afinidad, calcula una serie de particiones para las celdas del vector TILES_VECTOR proporcionado en la consulta; en nuestro ejemplo, el gestor de base de datos calculó que la consulta debe enviarse únicamente a 4 nodos -que son los que contienen datos para dichas particiones- de los 128 que conforman el clúster:
- Nodos seleccionados para la búsqueda colocada: 1 2 3 4 .
Conclusiones
Entender la computación colocada y definir correctamente tanto las claves de afinidad como la forma de colocar las consultas es crucial cuando trabajamos con miles de millones de registros en bases de datos distribuidas en clúster. No olvides:
- Elegir una plataforma que soporte computación colocada como Apache Ignite o GridGain.
- Estudiar tu modelo de datos para elegir correctamente la clave de afinidad que se utilizará para colocar los datos y colocar las consultas.
- Colocar las consultas siempre que sea posible, para reducir el consumo de recursos e incrementar el rendimiento de tu sistema.
En términos generales, la computación colocada en un sistema clusterizado y particionado ofrece las siguientes ventajas:
- Optimiza el consumo de recursos porque cada dato se almacena en un nodo concreto del clúster[1].
- Mejora notablemente el rendimiento del análisis de datos porque las computaciones se realizan en nodos concretos del clúster.
- Incrementa el rendimiento general del sistema, al minimizar el movimiento de datos y evitar computaciones innecesarias en nodos que sabemos que no tienen datos.
Si quieres profundizar en este tema, puedes encontrar más detalles en la documentación de indexación Avanzada para Apache Ignite y colocación por afinidad.
- 1.Algunas plataformas de computación distribuida, como Apache Ignite o GridGain, permiten tener backups de datos particionados en otros nodos de tu clúster para asegurar una alta tolerancia a fallos. ↩