En artículos anteriores hemos hablado sobre el alto grado de productividad de Mule ESB y sobre las capacidades de computación distribuida de GridGain.
¿Y si pudieras unir lo mejor de ambas tecnologías?
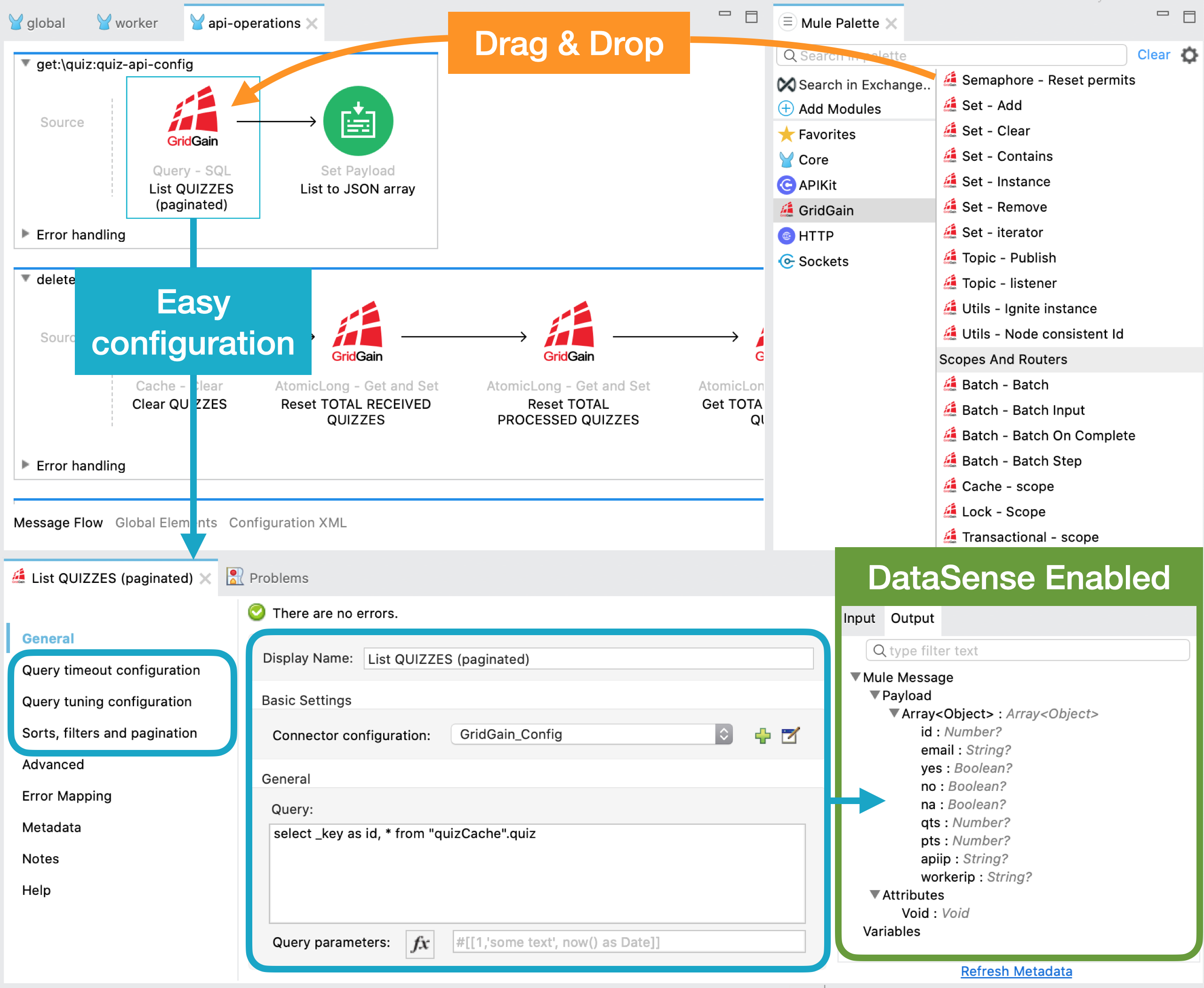
Con el conector de GridGain para Mule puedes llevar toda la potencia de la computación distribuida de GridGain a tus aplicaciones de Mule al más puro estilo Drag & Drop de Anypoint Studio, reduciendo de forma considerable el tiempo de desarrollo.
Todo ello, gracias a la facilidad con la que puedes configurar las operaciones y a la resolución automática de las estructuras de mensajes que entran y salen de las mismas mientras diseñas - DataSense.
Además, puedes usarlo tanto con Mule Community Edition - kernel - como con Mule Enterprise Edition (on-premise y CloudHub).
Características
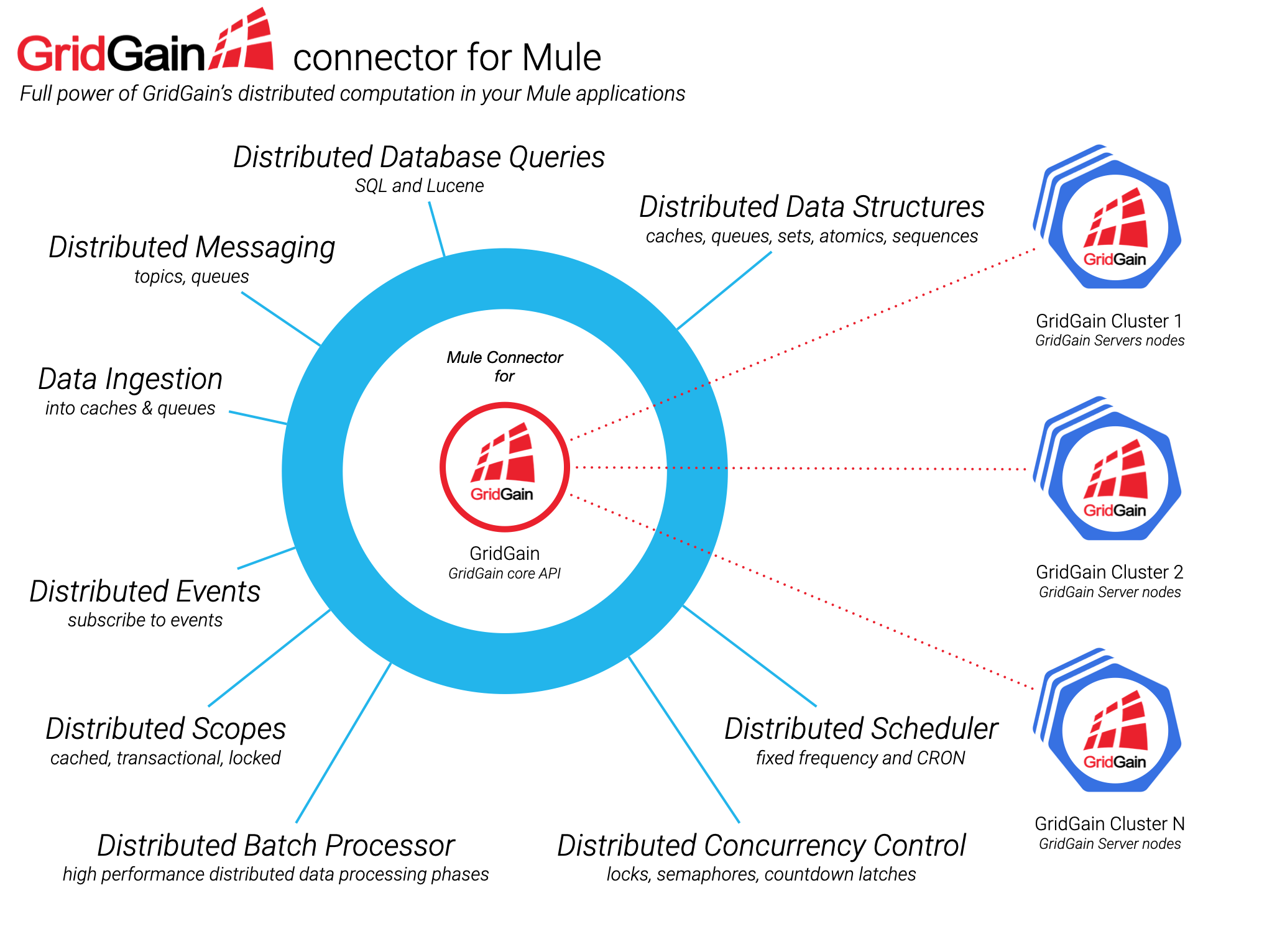
El conector de GridGain para Mule pone a disposición de tus aplicaciones de Mule toda la potencia de GridGain:
- Estructuras de control de concurrencia distribuidas - Cerrojos (locks), semáforos y cuenta atrás.
- Estructuras de datos atómicas distribuidas - enteros, referencias, secuencias y sellos.
- Estructuras de datos distribuidas de alto nivel - conjuntos, topics, colas y cachés.
- Consultas de datos usando SQL y Lucene.
- Ámbitos (scopes) de ejecución distribuidos, transaccionales, cacheados y de acceso exclusivo (locks).
- Programador de tareas distribuido.
- Trabajos en lote distribuidos.
Casos de uso típicos
- Sincronización de operaciones en clúster utilizando las herramientas de control de concurrencia de GridGain.
- Escalado de tus procesos (distribución de carga de procesamiento en clúster) con la ayuda de las estructuras de datos distribuidas de GridGain.
- Consulta y análisis de la información almacenada en tu clúster de GridGain utilizando SQL o Lucene.
- Cacheo clusterizado del resultado de la ejecución de una cadena de procesadores de Mule, que eventualmente podría ser pesada, para mejorar el rendimiento.
- Diseño de procesos por lotes que se ejecutarán de manera distribuida.
- Programación de la ejecución de procesos en clúster.
- Ingesta de datos de forma masiva.
¿Quieres ver un ejemplo?
Echa un vistazo al artículo sobre Computación distribuida con Mule y Kubernetes.
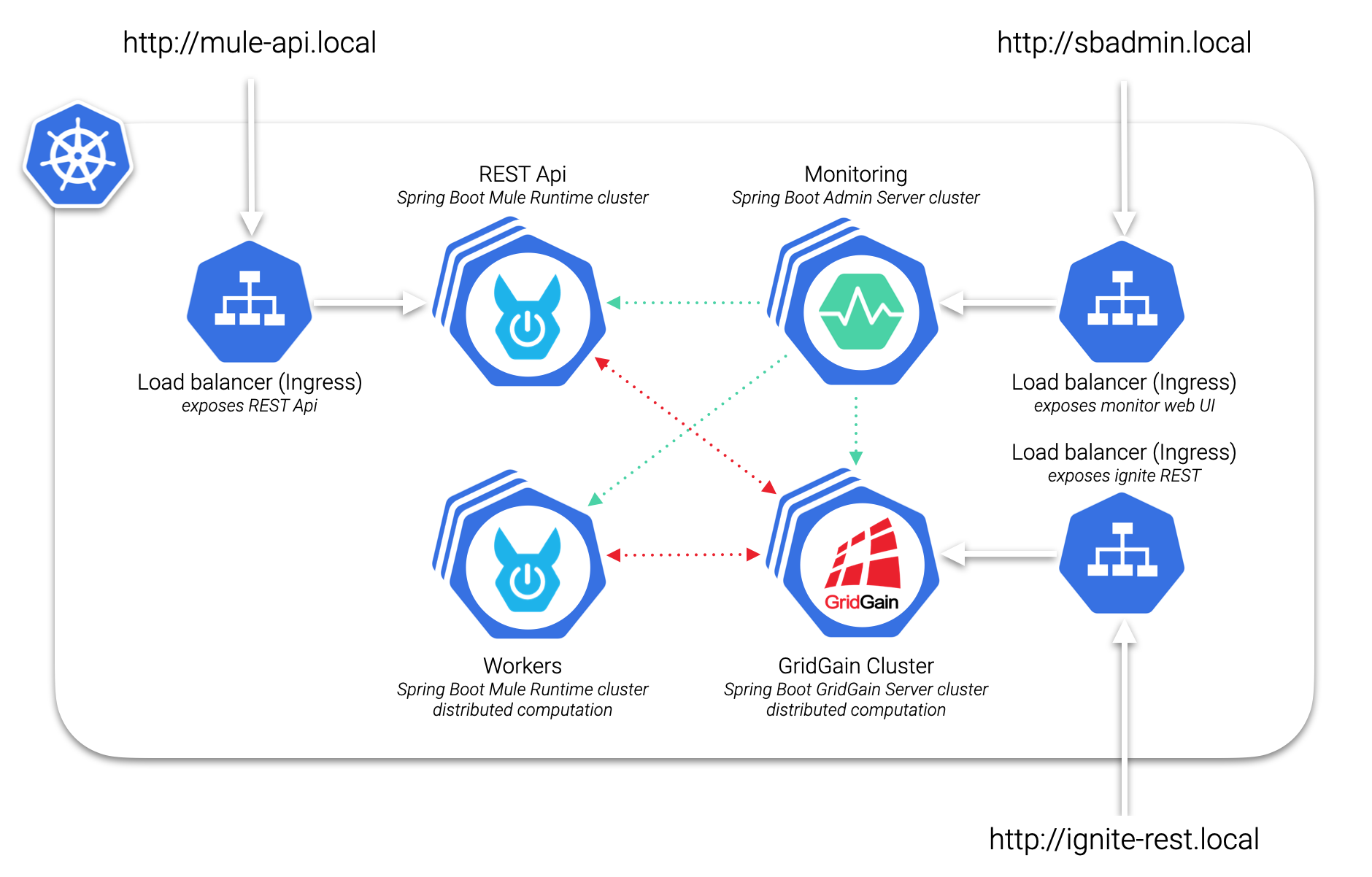
Puedes encontrar más ejemplos en nuestro repositorio de GitHub.